
Stockages distribués
Introduction
Que le lecteur pardonne l’emploi abusif du néologisme « scalabilité », mais il est difficile de trouver une traduction à la fois concise et complète de cette caractéristique anglophone (scalability) des systèmes informatiques qui consiste à étendre la capacité de stockage et de calcul d’un système pour répondre à une montée en charge (par pics ou continue). On peut procéder tant de manière verticale (en ajoutant des disques durs, de la mémoire ou des processeurs à un seul serveur physique) que de manière horizontale en ajoutant des serveurs physiques à côté de la machine originelle. On parle de scalabilité dès lors qu’il faut s’adapter de manière élastique et transparente à la montée en charge d’un système. Cela se produit très fréquemment dans les startups dont le produit phare (application web ou mobile en général), victime de son succès, repose sur une infrastructure qui n’est plus dimensionnée pour répondre à toutes les sollicitations de ses utilisateurs.
Ce chapitre aborde les thématiques ouvertes par les solutions que les ingénieurs ont apportées à cette problématique de gestion de la montée en charge ou scalabilité...
Big Data et scalabilité
S’il est un sujet qui fait couler beaucoup d’encre depuis 2010, c’est bien celui du Big Data. Quand on parle de scalabilité, on parle en réalité de changement d’échelle : jusqu’à présent on se contentait de mener des analyses statistiques sur des populations très réduites et représentatives de l’ensemble à étudier (c’est-à-dire un échantillon) au prix d’une analyse a priori, de postulats bien posés et de modèles mathématiques ad-hoc fonctionnant sur des zones d’équilibre de la population.
Ce qui change avec le Big Data, c’est qu’il n’est plus nécessaire de restreindre la taille de la population à un échantillon, on peut désormais travailler avec l’intégralité des données pour peu que l’on dispose d’une infrastructure dimensionnée en fonction du volume de données à traiter. Finalement, la seule limite n’est pas tant le ciel que le compte bancaire.
1. Les enjeux
Toute ressemblance avec un discours marketing s’avérerait fortuite : le Big Data prend sa source aux 3V, autrement dit Volume, Variété et Vélocité. Le Big Data est un nouveau marché bâti sur la croyance que l’on peut extraire de nouveaux filons de valeur en excavant les tonnes de transactions, les logs applicatifs, les traces de parcours utilisateur et plus généralement la volumétrie exponentiellement croissante de données fabriquées dormant pour la plupart dans les disques durs ou les appliances (machines dont la principale caractéristique est de pouvoir être simplement branchées pour fonctionner immédiatement de manière parfaitement opérationnelle) des systèmes d’information.
Les systèmes Big Data s’appuient sur du stockage "bon marché" et des technologies open source dont Hadoop est le fer de lance. L’enjeu pour les organisations est de s’offrir à moindre coût la capacité de calcul nécessaire à traiter de grosses quantités de données, en sortant du carcan des éditeurs avec leurs formats propriétaires, économisant au passage leurs coûts...
Hadoop et le Big Data
Hadoop est un projet open source hébergé par la fondation Apache. Il a été initié par Doug Cutting et Mike Cafarella en 2005. C’est un framework écrit en Java pour du stockage distribué et le traitement parallèle de jeux de données très volumineux, écrit pour s’exécuter sur du matériel informatique standard, peu coûteux en tenant compte du fait que les pannes matérielles sont communes et qu’elles doivent être gérées par le logiciel.
Hadoop est devenu en peu de temps le nouveau Graal des consultants et des DSI apôtres du Big Data en tant que source infinie de richesses pour l’entreprise, mais il faut bien savoir que sans un flux de données fiable et complet, un cluster Hadoop n’est rien d’autre qu’un chauffage extrêmement onéreux et difficile à assembler.
1. HDFS : un système de fichiers distribué
Il existe bien sûr d’autres systèmes de fichiers distribués, comme notamment le GFS (Google File System) son prédécesseur qui a fortement inspiré Doug Cutting en 2003 lorsqu’est paru l’article « The Google File System » décrivant les principes d’un système de stockage des fichiers distribué sur une grappe (cluster) de machine à bas prix, résistant aux pannes matérielles tout en proposant une puissance de calcul élastique inégalée.
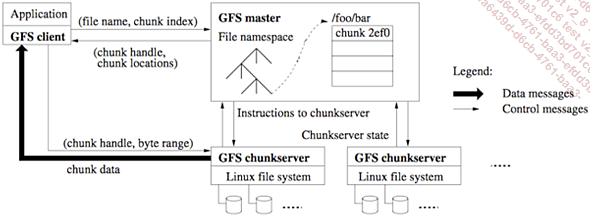
Figure 10.1 : Architecture du Google File System (source : http://static.googleusercontent.com/media/research.google.com/fr//archive/gfs-sosp2003.pdf)
Les exigences du système HDFS sont les suivantes :
-
Gestion des pannes : la défaillance est la norme plutôt que l’exception, d’autant plus qu’une instance d’HDFS sera déployée sur des centaines, voire des milliers de nœuds et servie par des processus Java complexes ayant une probabilité non nulle de défaillir. Il est donc impératif de s’adosser à une architecture prévoyant la tolérance aux pannes de manière native.
-
Accès streaming aux données : les applications qui fonctionnent sur HDFS ont besoin d’un accès en continu à leurs jeux de données....
Stockages NoSQL
Nous venons de voir comment Hadoop avec son système de fichiers distribué permet de traiter efficacement des fichiers d’une taille considérable sur un cluster de machines. Les fichiers en question sont des fichiers texte (TextFile) ou binaires (SequenceFile), généralement mis à plat, sous la forme de CSV (données en colonnes séparées par des virgules). Bien que ce format soit totalement ouvert et simple à manipuler, il ne couvre pas toutes les contraintes d’accès aux données : dans HDFS les fichiers ne sont pas modifiables, on ne peut qu’y ajouter des lignes à la fin et les temps d’accès en lecture aléatoire ne sont pas satisfaisants pour un usage de type base de données. Voilà pourquoi d’autres formes de stockage Big Data existent conjointement à HDFS.
1. NoSQL ou la fin des formes normales
Les technologies Big Data sont pour la plupart estampillées NoSQL (Not Only SQL) ce qui veut dire qu’elles s’affranchissent des six formes normales prônées par MERISE au prix d’une certaine redondance des données.
Dans l’informatique décisionnelle, et le monde relationnel en particulier, on avait pour dogme de bâtir des référentiels garantissant l’unicité des entités d’une base de données afin d’éliminer toute redondance. Les formes normales permettent aussi de limiter l’espace occupé par les données, elles favorisent la cohérence et les propriétés transactionnelles des SGBDR et facilitent la mise à jour des données. Toutefois, l’arrivée de nouveaux types de bases de données remet en question ce paradigme ancestral : désormais, avec l’avènement des technologies modernes et surtout la baisse des coûts de stockage, on se permet de dupliquer les champs, de tout mettre à plat en enlevant les jointures et en faisant « descendre » les champs dans des entités agrégées. Là où autrefois on avait une table pour les clients et une autre pour leurs adresses, reliées par des clés primaires et étrangères, on n’en a maintenant plus qu’une seule qui contiendra l’ensemble...