
La librairie standard STL
Introduction
L’inventeur de C++, Bjarne Stroustrup, a travaillé sur des projets de développement très importants. Les premières applications de C++ ont été réalisées dans le domaine des télécommunications, domaine qui réclame des outils de haut niveau. Certes, les classes favorisent l’abstraction, mais un programme n’est pas composé uniquement d’interfaces et d’implémentations.
À la conception du logiciel, le développeur doit déterminer la limite de réutilisation des réalisations précédentes. Derrière le terme « réutilisation », on entend souvent le fait de copier-coller certaines parties de code source. Quels sont les éléments qui se prêtent le mieux à cette opération ? Les classes, naturellement, le modèle orienté objet étant construit autour du concept de réutilisation. Mais on trouve également des structures de données, des fonctions spécialisées, des pièces algorithmiques de natures diverses, n’étant pas encore parvenues à la maturité nécessaire à la formation de classes.
Les modules décrivent un découpage assez physique des programmes. Ainsi, un fichier de code source .h ou .cpp peut être considéré...
Organisation des programmes
1. Espaces de noms
Le langage C ne connaît que deux niveaux de portée : le niveau global, auquel la fonction main() appartient, et le niveau local, destiné aux instructions et aux variables locales. Avec l’apparition de classes, un niveau supplémentaire s’est installé, celui destiné à l’enregistrement des champs et des méthodes. Puis l’introduction de la dérivation (héritage) et des membres statiques a encore nuancé la palette des niveaux de portée.
Pour les raisons évoquées en introduction, il devenait nécessaire de structurer l’espace global. Pour n’en retenir qu’une, l’espace global est trop risqué pour le rangement de variables et de fonctions provenant de programmes anciens. Les conflits sont inévitables.
On peut alors partitionner cet espace global à l’aide d’espaces de noms :
namespace Batiment
{
double longueur;
void mesurer()
{
longueur=50.3;
}
} ;
namespace Chaines
{
int longueur;
void calcule_longueur(char*s)
{
longueur=strlen(s);
}
} ; Deux espaces de noms, Batiment et Chaines, contiennent tous les deux une variable nommée longueur, d’ailleurs de type différent. Les fonctions mesurer() et calcule_longueur() utilisent toujours la bonne version, car la règle d’accessibilité est également vérifiée dans les espaces de noms : le compilateur cherche toujours la version la plus proche.
Pour utiliser l’une ou l’autre de ces fonctions, la fonction main() doit recourir à l’opération de résolution de portée :: ou bien à une instruction using :
int main(int argc, char* argv[])
{
Batiment::mesurer();
printf("La longueur du bâtiment est %g\n",Batiment::longueur);
using Chaines::longueur;
Chaines::calcule_longueur("bonjour"); ...Flux C++ (entrées-sorties)
La librairie STL gère de nombreux aspects des entrées-sorties. Elle inaugure une façon de programmer pour rendre persistants les nouveaux types définis à l’aide du langage C++.
L’équipe qui l’a conçue à la fin des années 1980 a eu le souci d’être conforme aux techniques en vigueur et de produire un travail qui résisterait au fil des ans.
Il faut reconnaître que la gestion des fichiers a énormément évolué depuis l’introduction de la bibliothèque standard : les bases de données relationnelles ont remplacé les fichiers structurés, et les interfaces graphiques se sont imposées face aux consoles orientées caractères.
Toutefois, les axes pris pour le développement de la librairie STL étaient les bons. Si l’utilisation des flux est un peu tombée en désuétude, leur étude permet d’y voir plus clair pour produire une nouvelle génération d’entrées-sorties. Aussi, le terminal en mode caractères continue son existence, la vitalité des systèmes Linux en est la preuve.
1. Généralités
Pour bien commencer l’apprentissage des entrées-sorties, il faut faire la différence entre fichier et flux. Un fichier est caractérisé par un nom, un emplacement, des droits d’accès et parfois aussi un périphérique. Un flux (stream en anglais) est un contenu, une information qui est lue ou écrite par le programme. Cette information peut être de plus ou moins haut niveau. À la base, on trouve naturellement l’octet, puis celui-ci se spécialise en donnée de type entier, décimal, booléen, chaîne... Enfin, on peut créer des enregistrements composés d’informations très diverses. Il est tout à fait logique de considérer que la forme de ces enregistrements correspond à la formation d’une classe, c’est-à-dire d’un type au sens C++.
Les flux C++ (que l’on appelle parfois flots en langue française) sont organisés en trois niveaux. Le premier - le plus abstrait - regroupe les ios_base, format d’entrée-sortie indépendant de l’état...
Classe string pour la représentation des chaînes de caractères
C’est un fait étonnant, la majorité des traités d’algorithmie n’étudient pas les chaînes en tant que telles. La structure de données s’en rapprochant le plus reste le tableau pour lequel on a imaginé une grande quantité de problèmes et de solutions.
Le langage C est resté fidèle à cette approche et considère les chaînes comme des tableaux de caractères. Ses concepteurs ont fait deux choix importants : la longueur d’une chaîne est limitée à celle allouée pour le tableau, et le codage est celui des caractères du C, utilisant la table ASCII. Dans la mesure où il n’existe pas de moyen de déterminer la taille d’un tableau autrement qu’en utilisant une variable supplémentaire, les concepteurs du langage C ont imaginé de terminer leurs chaînes par un caractère spécial, de valeur nulle. Il est vrai que ce caractère n’a pas de fonction dans la table ASCII, mais les chaînes du C sont devenues très spécialisées, donc très loin de l’algorithmie générale.
L’auteur de C++, Bjarne Stroustrup, a souhaité, pour son langage, une compatibilité avec le langage C, mais aussi une amélioration du codage prenant en compte différents formats de codage, ASCII ou non.
1. Représentation des chaînes dans la librairie STL
Pour la librairie STL, une chaîne est un ensemble ordonné de caractères. Une chaîne s’apparente donc fortement au vector, classe également présente dans la bibliothèque. Toutefois, la chaîne développe des accès et des traitements qui lui sont propres, soutenant ainsi mieux les algorithmes traduits en C++.
Les chaînes de la bibliothèque standard utilisent une classe de caractères pour s’affranchir du codage. La librairie STL fournit le support pour les caractères ASCII (char) et pour les caractères étendus (wchar_t), mais on pourrait très bien envisager de développer d’autres formats destinés à des algorithmes à base de chaînes. Le génie génétique emploie des chaînes...
Conteneurs dynamiques
Une fonction essentielle de la bibliothèque standard est de fournir des mécanismes pour supporter les algorithmes avec la meilleure efficacité possible. Cet énoncé comporte plusieurs objectifs contradictoires. Les algorithmes réclament de la généricité, autrement dit des méthodes de travail indépendantes du type de données à manipuler. Le langage C utilisait volontiers les pointeurs void* pour garantir la généricité mais cette approche entraîne une perte d’efficacité importante dans le contrôle des types, une complication du code et finalement de piètres performances. L’efficacité réclamée pour STL s’obtient au prix d’une conception rigoureuse et de contrôles subtils des types. Certes, le résultat est un compromis entre des attentes parfois opposées mais il est assez probant pour être utilisé à l’élaboration d’applications dont la sûreté de fonctionnement est impérative.
Les concepteurs de STL ont utilisé les modèles de classes pour développer la généricité. Les modèles de classes et de fonctions sont étudiés en détail au chapitre Programmation orientée objet, et leur emploi est assez simple. Une classe est instanciée à partir de son modèle en fournissant les paramètres attendus, généralement le type de données effectivement pris en compte pour l’implémentation de la classe. Il faut absolument différencier cette approche de l’utilisation de macros (#define) qui provoque des résultats inattendus. Ces macros se révèlent très peu sûres d’emploi.
Une idée originale dans la construction de la bibliothèque standard est la corrélation entre les conteneurs de données et les algorithmes s’appliquant à ces conteneurs. Une lecture comparée de différents manuels d’algorithmie débouche sur la conclusion que les structures de données sont toujours un peu les mêmes, ainsi que les algorithmes s’appliquant à ces structures. Il n’était donc pas opportun de concevoir...
Algorithmes
Un conteneur offre déjà un résultat intéressant mais la bibliothèque standard tire sa force d’un autre aspect : les conteneurs sont associés à des fonctions générales, des algorithmes. Ces fonctions utilisent presque toutes des itérateurs pour harmoniser l’accès aux données d’un type de conteneur à l’autre.
1. Opérations de séquence sans modification
Il s’agit principalement d’algorithmes de recherche et de parcours.
|
for_each() |
Exécute l’action pour chaque élément d’une séquence. |
|
find() |
Recherche la première occurrence d’une valeur. |
|
find_if() |
Recherche la première correspondance d’un prédicat. |
|
find_first_of() |
Recherche dans une séquence une valeur provenant d’une autre. |
|
adjacent_find() |
Recherche une paire adjacente de valeurs. |
|
count() |
Compte les occurrences d’une valeur. |
|
count_if() |
Compte les correspondances d’un prédicat. |
|
mismatch() |
Recherche les premiers éléments pour lesquels deux séquences diffèrent. |
|
equal() |
Vaut true si les éléments de deux séquences sont égaux au niveau des paires. |
|
search() |
Recherche la première occurrence d’une séquence en tant que sous-séquence. |
|
find_end() |
Recherche la dernière occurrence d’une séquence en tant que sous-séquence. |
|
search_n() |
Recherche la nième occurrence d’une valeur. |
Nous proposons un exemple de recherche de valeur dans un vecteur de chaînes char* :
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main(int argc, char* argv[])
{
vector<char*> tab;
tab.push_back("Sonate");
tab.push_back("Partita");
tab.push_back("Cantate");
tab.push_back("Concerto");
tab.push_back("Symphonie");
tab.push_back("Aria");
tab.push_back("Prélude");
vector<char*>::iterator pos;
char*mot="Concerto";
pos=find(tab.begin(),tab.end(),mot); ...Des apports du C++ moderne
Le langage C++ fait l’objet de révisions et d’innovations. Depuis la version de référence dite C++ 98 publiée en 1998, d’autres versions l’ont propulsé vers la modernité. Les standards C++ 11, C++ 14, C++ 17, C++ 20 et maintenant C++ 23 comprennent des fonctionnalités très puissantes jusque-là disponibles uniquement dans d’autres langages initialement conçus bien après C++.
Nous présentons ici de nouvelles possibilités en rapport avec le langage et l’algorithmique.
1. Les lambda-expressions
En C++, une lambda-expression (ou lambda) est une fonction anonyme (désignée par le terme fermeture ou closure en anglais) appelée à l’endroit même où elle est définie. C’est un moyen pratique pour décrire des petits algorithmes sans chercher à rendre ces fonctions réutilisables.
La lambda est une notation composée des éléments suivants :
[capture] (paramètres) mutable exception { corps } La capture permet à la lambda de travailler avec les variables déclarées dans la portée qui la définit, en référence & ou en valeur =. La capture par défaut peut être par valeur =, ce qui signifie que la lambda reçoit une « copie » des variables apparaissant dans le corps d’instruction. Si la capture est par référence &, la lambda a la faculté de modifier les variables.
Les paramètres sont optionnels, bien que fréquemment une lambda reçoive des éléments à tester, à comparer, à évaluer, à traiter, etc.
Le mot-clé mutable est aussi optionnel. En règle générale, l’opérateur d’appel à une lambda est const par valeur, mais la présence de mutable annule cette règle, en permettant au corps d’instruction de modifier localement des variables capturées par valeur.
L’indication d’exception par throw ou noexcept est facultative, comme pour l’ensemble des fonctions C++.
Le type de retour est déduit par le compilateur à partir du corps. Par défaut, il s’agit de void, à moins qu’une...
Introduction à la bibliothèque boost
La bibliothèque boost n’est pas un concurrent de la librairie STL, mais plutôt un complément ou son prolongement. De fait, plusieurs modules du référentiel boost ont été intégrés dans la bibliothèque standard au fil des versions C++ 14 à C++ 17. Les deux bibliothèques STL et boost fonctionnent donc très bien ensemble.
1. Installation de la bibliothèque
Il existe plusieurs moyens d’installer la bibliothèque au sein d’un projet. Sous Linux, on peut suivre les instructions du site https://boost.org/ pour récupérer un package de sources ou de binaires.
Depuis Visual Studio, le moyen le plus direct consiste à télécharger un package NuGet. Depuis le menu Projet, utiliser la commande Gérer les packages NuGet. Indiquer boost dans la zone de recherche de l’onglet Parcourir. Le catalogue des packages présente alors la bibliothèque complète ainsi que des volumes de cette bibliothèque.
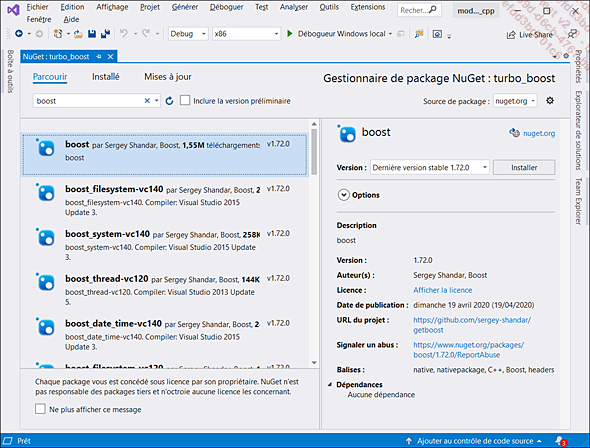
Après avoir cliqué sur le bouton Installer, le gestionnaire de package demande de confirmer l’installation de la bibliothèque au sein du projet :
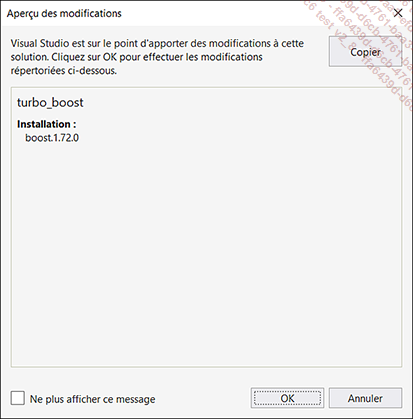
La confirmation déclenche le processus de téléchargement du package NuGet (au niveau de la solution Visual Studio) et d’installation de la bibliothèque...
Travaux pratiques
L’interprète tiny-lisp s’appuie largement sur la librairie STL. Voici des précisions sur la classe Variant implémentée à grand renfort d’objets issus de la bibliothèque standard.
1. La classe Variant
Variant est le type de données universel de tiny-lisp. Cela peut être un symbole, un nombre, une liste (de Variant), une procédure.
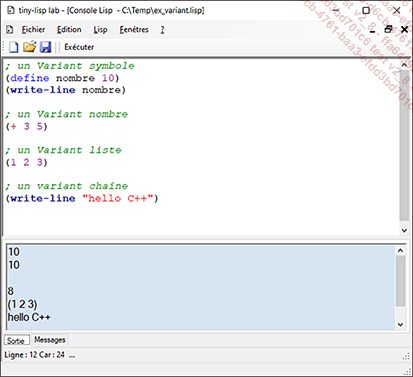
Dans tiny-lisp, l’objet Variant fait partie d’un environnement, un conteneur doté d’une table des symboles. Cette structure est nécessaire à l’exécution des fonctions et des lambda-expressions LISP pour passer les paramètres et créer des variables locales.
enum variant_type
{
Symbol, Number, List, Proc, Lambda, Chaine
};
// definition à venir ; Variant et Environment se référencent
mutuellement
struct Environment;
// un Variant représente tout type de valeur Lisp
class Variant {
public:
// fonction qui renvoie Variant et qui prend comme argument variants
typedef Variant(*proc_type) ( const std::vector<Variant>& );
typedef std::vector<Variant>::const_iterator iter;
typedef std::map<std::string, Variant> map;
// types pris dans l'énumération : symbol, number, list, proc ou lamda
variant_type type;
// valeur scalaire
std::string val;
// valeur list
std::vector<Variant> list;
// valeur lambda
proc_type proc;
// environnement
Environment* env;
// constructeurs
Variant(variant_type type = Symbol) : type(type) , env(0), proc(0) {
}
Variant(variant_type...