
Gérer les observations
Rappels importants
1. Définitions
a. L’observation
Quel que soit le moment où un usager ou un membre du projet croit détecter une anomalie, il doit émettre une observation.
Cette observation n’est pas une anomalie mais un document, le rapport décrivant un comportement du logiciel qui fait que son rapporteur s’interroge.
Qualifier immédiatement une observation d’anomalie est donc présomptueux et nous recommandons une certaine vigilance afin que la confusion des concepts ne vienne pas altérer le processus de qualification qui traite les observations.
L’anomalie est ce qui nécessite la correction du logiciel : c’est donc au dernier moment et lorsqu’il y a un consensus entre MOA et MOE sur l’observation que l’on pourra la qualifier d’anomalie.
Une fois ce raccourci trop facile évité, nous pouvons définir l’observation. C’est avant tout une description factuelle qui est caractérisée par :
-
L’environnement dans lequel l’observation est faite, ou a minima, la distinction entre l’environnement de production et tout autre environnement, car une anomalie détectée en production motivera peut être une intervention en urgence.
-
Le nom du rapporteur de l’observation, si possible sa fonction au sein de l’entreprise (c’est une donnée qui informellement peut participer à estimer l’urgence d’une intervention !).
-
Le ou les logiciels faisant l’objet de l’observation, et les lieux précis où la manifestation est vue (les exigences fonctionnelles concernées, donc).
-
La date à laquelle l’observation est faite.
-
La liste des actions réalisées qui a mené à la manifestation qui motive la déclaration.
-
Éventuellement, la reproductibilité, c’est-à-dire la capacité de pouvoir réitérer la survenance de l’observation en ré-exécutant les actions indiquées. Si la reproductibilité n’a pas été évaluée, l’indiquer aussi.
-
La description du constat, éventuellement des pièces jointes (captures d’écran, rappel des spécifications…).
-
Le caractère bloquant ou non de l’impact, c’est-à-dire...
Processus de gestion des incidents de production
Nous détaillons ici le processus mentionné dans les sections précédentes.
1. Principes organisationnels
a. Formaliser le ou les workflows documentaires
Nous considèrerons dans un premier temps que la MOA est une structure monolithique en charge de collecter les besoins et incidents de production de l’ensemble du système d’information, dans tous les métiers.
Le processus de gestion des incidents de production serait alors le suivant :
1) Ouverture directe ou indirecte d’une observation.
2) Soumission à un responsable qualité logicielle membre permanent de la MOA.
3) Analyse par ce responsable permettant de qualifier l’observation.
4) Lancement manuel du processus suivant selon la nature de l’observation.
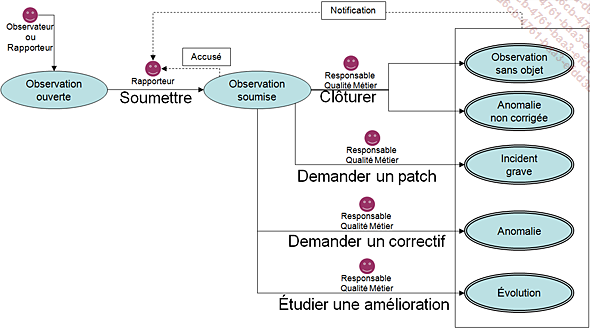
Le premier point à retenir dans ce processus concerne son ouverture : celui qui fait une observation n’est pas nécessairement celui qui la rapporte.
En effet, deux situations sont possibles car l’observation peut très bien être réalisée par une personne étrangère à l’entreprise (un partenaire, un client, un internaute…) pour laquelle un retour n’est d’ailleurs pas toujours possible.
Le rapporteur en charge d’initialiser le processus d’ouverture informe donc l’observateur de manière informelle que son signalement a été pris en compte, puis il initialise le workflow par délégation ou en son nom propre s’il est lui-même l’observateur.
Ce rapporteur sera le plus souvent une personne du métier, proche de la MOA par définition. Et elle saisira dans l’outil de collecte des incidents de production des informations permettant au destinataire de qualifier l’observation.
Les informations vitales sont ici :
-
l’identité du rapporteur,
-
l’impact (financier ? perte d’information ? image de marque ?),
-
la fréquence de l’impact (minute, heure, quotidienne, … aléatoire),
-
sa description.
Dès lors que l’observation est soumise à un responsable qualité métier, ce dernier a les éléments factuels qui lui permettront d’estimer laquelle des quatre options qui s’offrent à lui est la bonne.
Premier cas de figure : l’observation...
Les anomalies remontées par la maîtrise d’ouvrage
Lors d’une recette purement fonctionnelle conduite par le métier, des anomalies peuvent être détectées. Nous détaillons ici comment gérer ce processus.
1. Principes organisationnels
a. Avec ou sans équipe de recette technique ?
Avant toute mise en place d’un processus de collecte des observations des recettes fonctionnelles, il faudra se poser la question du contexte même du projet.
Il est bien évident qu’en l’absence d’une structure en charge des recettes techniques, c’est la MOA qui s’y substitue en réalisant des recettes à la fois techniques et fonctionnelles.
Dès lors, peu importe l’étape du projet où l’anomalie est détectée (seul l’environnement de recette change peut-être entre recette technique et recette fonctionnelle, pas ses acteurs).
Dans un tel cas, nous vous renvoyons à la section relative à la remontée des observations dans une recette technique pour implémenter ce processus.
En revanche, dès lors qu’il existe une équipe de recette technique, le processus de collecte des observations en recette fonctionnelle diffère.
b. Définir un support de collecte
Dès lors que l’équipe de recette technique existe et qu’elle est distincte de l’équipe des recettes métier, nous préconisons que les observations soient saisies dans le même outil de recette en définissant toutefois deux nuances :
-
L’observation doit clairement montrer qu’elle est réalisée dans un environnement de recette métier. Il ne suffit pas de mentionner que le rapporteur n’appartient pas à l’équipe de recette technique mais à la MOA pour comprendre qu’il s’agit d’un événement détecté en recette fonctionnelle.
-
Le processus de qualification de l’observation détectée en recette fonctionnelle n’est pas exactement le même qu’en recette technique :
-
Le rapporteur appartient à la MOA et non à l’équipe de recette technique.
-
L’application testée n’est pas nécessairement dans la même version que celle à disposition...
Les anomalies détectées lors d’une recette technique
La présente section intéresse également les MOA pour les recettes fonctionnelles dès lors qu’il n’existe pas d’équipe de recette technique dédiée au projet et que la MOA s’y substitue.
1. Principes organisationnels
a. Formaliser le workflow documentaire
Nous proposons le workflow documentaire suivant pour modéliser le processus de qualification d’une observation entre une MOA, une MOE et une équipe de recette technique.
Les principes de base de ce workflow sont :
-
Que le CP Test fait office de trieur des observations en amont (pour éviter redondance et observation sans objet).
-
Que le CP MOA joue le rôle d’arbitre entre le CP Recette et le CP MOE lorsqu’il y a désaccord sur la nature d’une observation.
-
Qu’il n’y a pas de cycle entre CP Test et CP MOE : le workflow ne doit pas devenir un tchat dans lequel chacun se renvoie la balle.
-
Que les correctifs une fois réalisés sont synchronisés dans un même lot, une même livraison.
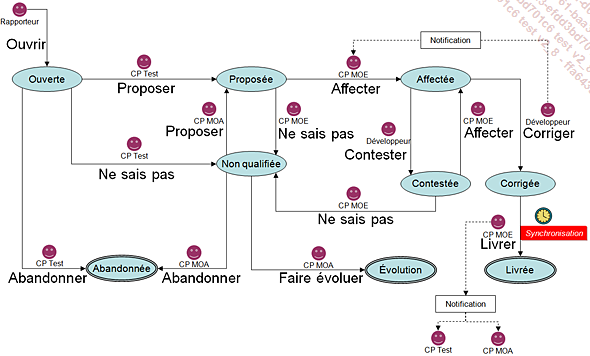
Ainsi, un rapporteur ouvre une observation à destination du responsable de la recette technique, un chef de projet test noté CP Test.
Ce rapporteur peut être un membre de l’équipe de recette technique ou bien le CP MOA qui ajouterait ainsi une observation détectée en recette fonctionnelle.
Le CP Test qui reçoit l’anomalie pourra alors :
-
Abandonner l’observation si elle est redondante, sans objet ou bien fait référence à une anomalie qui ne peut être corrigée. Il y a bien sûr un motif décrivant l’abandon qui est par ailleurs un état terminal. Éventuellement, une observation abandonnée pourrait repasser au statut Ouverte.
-
Ne pas savoir statuer sur la qualification de l’observation, auquel cas elle sera soumise au CP MOA car non qualifiée.
-
Proposer l’observation au CP MOE car probablement d’origine anomalistique.
La réponse du CP MOE est alors simple :
-
Il admettra que l’observation est une anomalie et demandera à un développeur la correction en l’affectant.
-
Ou bien il ne sera pas d’accord avec le CP Test et ne pourra que la transmettre pour arbitrage au CP MOA.
Lorsqu’un développeur reçoit...



