
Gestion des actifs et haute disponibilité
Gestion des commutateurs et routeurs
1. Outils et interfaces d’administration
a. Interfaces CLI
Lors du choix d’un équipement réseau, particulièrement d’un routeur ou d’un commutateur, se pose la question de la gestion de l’équipement : ce dernier est-il manageable ? C’est-à-dire paramétrable et donc adaptable au réseau auquel il est destiné.
Il existe des équipements non manageables vendus en général à bas coût par les constructeurs et dès lors que l’on commence à monter en prix (et donc en gamme), apparaît une interface de gestion sur les équipements. Un matériel vendu en tant qu’« équipement adapté à l’entreprise » se doit d’être manageable bien que ce ne soit pas toujours le cas.
Le mode d’administration le plus basique, mais parfois le plus efficace pour un équipement réseau se présente via une interface minimaliste permettant d’entrer des lignes de commandes, on parle de CLI (Command Line Interface). Ces commandes CLI dépendent de l’équipement en question et du constructeur. Chaque constructeur défini et implémente ses propres commandes ; rappelons en effet que la majorité des systèmes d’exploitation des éléments actifs d’un réseau sont propriétaires.
Par exemple, Cisco développe depuis sa création au début des années 80 un OS appelé l’IOS (Internetwork Operating System). C’est cet IOS qui a fait la réussite du constructeur dans le monde du réseau.
L’accès à la CLI peut s’effectuer via le réseau IP, donc à partir de n’importe quel poste connecté au réseau LAN ou WAN via un protocole tel que TELNET et son homologue beaucoup plus sécurisé SSH. Ces deux protocoles sont utilisés également lors de l’administration de serveurs et permettent d’entrer des commandes simplement sur un équipement distant, comme si on était directement connecté physiquement sur ce dernier.
C’est comme cela par exemple qu’un FAI peut vérifier la connexion internet d’un de ses clients :...
Haute disponibilité
1. Introduction
L’administrateur réseau a notamment pour rôle d’assurer le fonctionnement du réseau et peut être amené à mettre en place certains mécanismes de tolérance de pannes selon le contexte et le taux de disponibilité que l’activité de l’entreprise demande.
Ce besoin de haute disponibilité entraînera l’utilisation d’un second lien physique, d’un second équipement actif, voire plus, pour prendre le relais en cas de panne. Les mécanismes de redondance peuvent se différencier selon le niveau sur lequel ils agissent, en référence au modèle OSI. On retrouve communément donc des mécanismes de H.A (Haute disponibilité ou High Availability en anglais) qui assureront une redondance au niveau 2 Ethernet comme le spanning-tree et l’agrégation, et d’autres qui s’attachent au niveau 3 IP comme des protocoles de routage dynamique, ou de redondance de routeurs tels que VRRP. Ce principe peut être également étendu à la couche applicative : clusters de serveurs web, machines virtuelles redondantes, etc.
Dans cette section, nous nous attacherons à parcourir les mécanismes de tolérance de panne que l’administrateur réseau peut être amené à mettre en place. Nous nous restreindrons ici aux mécanismes de niveau 2 et de niveau 3 parmi les plus courants et les plus simples à mettre en place.
2. Redondance des liens physiques et agrégation
a. Principe du spanning-tree
Le spanning-tree est un protocole de niveau 2 normalisé 802.1D conçu initialement pour éviter la formation de boucles réseau. Une boucle réseau de niveau 2 entraîne ce que l’on appelle une tempête de broadcast, c’est-à-dire des trames circulant indéfiniment sur le réseau provoquant à terme une paralysie complète du réseau ou en tout cas du VLAN en question.
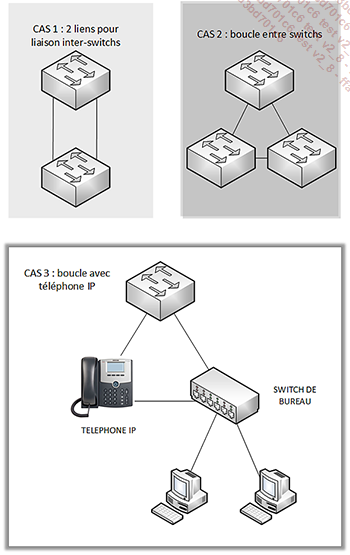
Trois exemples de câblage entraînant une boucle réseau
Il existe de multiples implémentations du spanning-tree propriétaires ou ouvertes dont les différences majeures se mesurent sur la rapidité de convergence de l’algorithme utilisé...


