
Modélisation et évaluation
Phase de modélisation
La phase de Modeling fait suite à la phase de préparation des données. Elle consiste à créer un ou plusieurs modèles permettant de réaliser la tâche déterminée en Business Understanding.
Ces modèles devront être améliorés, affinés, évalués et comparés, de manière à ne proposer en phase d’Evaluation que le ou les plus adaptés au contexte métier.
Cette modélisation peut amener à des modifications des données, que ce soit leur format, l’unité, ou leur type. Ces modifications impliquent de pouvoir retourner en phase de Data Preparation, et ces itérations peuvent se faire plusieurs fois par jour.
En effet, certains algorithmes auront des contraintes fortes sur les données acceptées en entrée. De plus, il peut arriver que l’ajout de données ou leur modification améliore les résultats. C’est par exemple généralement le cas de la normalisation.
En pratique, c’est à partir de la phase de Modeling que la librairie Scikit-learn sera la plus utilisée. Elle prend la suite de Pandas, qui était utilisée pour le chargement, l’analyse et la préparation des données.
Scikit-learn est une librairie très complète...
Création d’un ensemble de validation
En phase de préparation des données, deux sous-ensembles ont été créés :
-
Le dataset d’apprentissage (ou train) qui sert à créer les modèles.
-
Le dataset de test qui sert à valider leur adaptation au cas réel et à les évaluer.
Pour la grande majorité des algorithmes, de nombreux hyperparamètres seront à déterminer. Ils servent à diriger et contrôler l’apprentissage. Selon les valeurs choisies, adaptées ou non, les résultats peuvent varier d’un modèle très performant à un modèle complètement inutilisable.
Le dataset de test ne peut pas être utilisé pour évaluer quels paramètres sont les meilleurs, sinon il y aurait un fort biais lors de l’évaluation.
Un troisième dataset est donc nécessaire : l’ensemble de validation. L’ensemble d’apprentissage va donc être séparé en un ensemble qui servira réellement à l’apprentissage et un qui servira à déterminer les paramètres.
Généralement, 10 % des données d’origine serviront à la validation. Cependant, comme pour la création de l’ensemble de test, plus il y a de données disponibles et...
Préparation des datasets
Dans les chapitres suivants seront utilisés les datasets Iris, Titanic et Boston. Ils doivent donc être chargés et mis au bon format pour pouvoir faire de la modélisation dessus.
Les préparations vues dans le chapitre précédent seront simplifiées au minimum pour créer des modèles. Les résultats ne seront donc pas optimisés.
Scikit-learn n’accepte que des paramètres numériques pour les différents algorithmes de Machine Learning. Toutes les variables catégorielles doivent donc être quantifiées.
Les données ne seront pas normalisées en amont. En effet, certains algorithmes n’en ont pas besoin et les données brutes seront alors gardées. Cependant, il ne doit plus y avoir de données manquantes et celles-ci doivent donc être supprimées ou imputées.
1. Dataset Iris
Ce dataset est assez simple, il ne contient que des variables numériques et aucune donnée manquante. Ne possédant pas d’ensemble de test, il faut en créer un.
Sa préparation complète est donc la suivante :
import pandas as pd
from sklearn.model_selection import train_test_split
# Chargement
iris_df = pd.read_csv("iris.csv")
# Séparation train - test
y = iris_df['class']
X = iris_df.drop(labels='class', axis=1)
train_X_iris, test_X_iris, train_y_iris, test_y_iris =
train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=42) 2. Dataset Titanic
Le dataset Titanic est plus complexe à préparer. Il contient...
Création des modèles
1. Processus itératif
Une fois les données prêtes, il faut créer les modèles. En pratique, il s’agit d’un processus fortement itératif selon le cycle suivant :
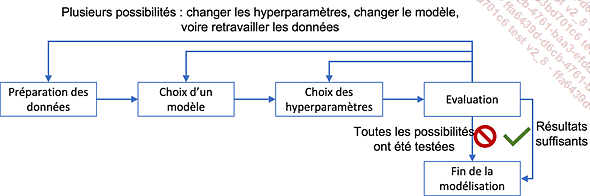
Au sein d’une itération CRISP-DM, cette phase s’arrêtera le plus souvent par manque de temps. Cependant, son impact sera important sur la présence ou non d’autres itérations ensuite :
-
Soit les résultats sont suffisamment bons, et la phase suivant l’évaluation sera le déploiement (mise en production).
-
Soit, malgré tous les essais, les résultats restent insuffisants, et le projet s’arrêtera, en accord avec le client. Cela peut arriver si les données fournies ne sont pas d’assez bonne qualité ou en quantité suffisante, ou encore si elles sont sans rapport avec la tâche à réaliser. Une autre cause d’arrêt peut être le manque d’algorithme performant sur cette tâche dans l’état de l’art. Il peut arriver que l’arrêt ne soit en fait qu’une pause, car de nouveaux algorithmes peuvent être mis au point ou de nouvelles données peuvent être collectées.
Dans tous les autres cas, une itération supplémentaire sera faite, en modifiant, au choix :
-
Les hyperparamètres du modèle en cours, surtout si les résultats semblent prometteurs.
-
Le modèle choisi, s’il apparaît qu’il ne donnera pas de bons résultats. Selon l’évaluation, le choix pourra se porter sur un modèle plus ou moins complexe.
-
Les données, en modifiant ou en rajoutant des étapes dans la préparation des données, par exemple pour transformer des données numériques en variables catégorielles ou l’inverse, ou en calculant de nouvelles variables issues des précédentes.
2. Création d’un modèle en Scikit-learn
Créer un modèle en Scikit-learn est très simple et se fait en trois étapes :
-
La création du modèle, via l’instanciation d’un algorithme (appelé estimator), et l’indication...
Amélioration des modèles (fine-tuning)
1. Optimisation des hyperparamètres
L’optimisation des hyperparamètres consiste à créer plusieurs apprentissages avec le même algorithme mais avec des hyperparamètres différents.
Selon les valeurs choisies, certains modèles pourront être très bien adaptés et donc performants ou au contraire inutilisables. De plus, pour les algorithmes possédant plusieurs hyperparamètres, ceux-ci sont souvent liés, et la modification d’un hyperparamètre peut nécessiter le changement de tous les autres.
En théorie, il faudrait donc tester tous les ensembles d’hyperparamètres possibles. Cette recherche exhaustive est en pratique impossible.
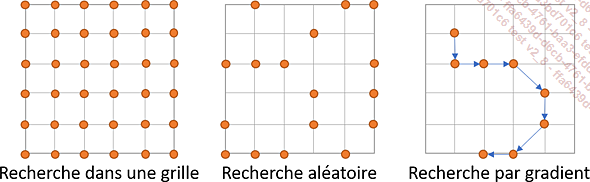
Les principales stratégies sont :
-
la recherche dans une grille (grid search) : pour chaque hyperparamètre, un nombre donné de valeurs est fourni, et la recherche essaiera toutes les combinaisons possibles ;
-
la recherche aléatoire (random search) : seul un sous-ensemble des combinaisons possibles sera testé. La recherche aléatoire peut prendre ses valeurs parmi des listes fournies ou en les sélectionnant sur des intervalles continus ;
-
la recherche par gradient (gradient-based optimization) : en fonction des résultats obtenus sur différents ensembles, la recherche sera guidée dans le sens du gradient vers l’optimisation de la métrique choisie.
2. Application en Scikit-learn
Seules les deux premières existent dans Scikit-learn. Il faut alors fournir à la méthode l’estimator utilisé, les hyperparamètres avec les valeurs ou les distributions, la ou les métriques à optimiser.
La première étape consiste, dans les deux cas, à définir une liste de paramètres à optimiser ainsi que les possibilités pour leur choix....
Méthodes ensemblistes
Les meilleurs résultats dans les challenges ne sont actuellement que très rarement obtenus via un seul modèle. C’est en utilisant plusieurs modèles, qui vont se cumuler et/ou se compenser, que les résultats sont les meilleurs.
En effet, avec plusieurs modèles différents, les erreurs d’un modèle en particulier pourront être compensées par les autres modèles. De plus, le résultat est généralement moins soumis au sur-apprentissage car la moyenne de plusieurs modèles va lisser les prédictions.
Pour cumuler plusieurs modèles, il existe trois approches :
-
Le bagging
-
Le boosting
-
Le stacking
1. Bagging
Le terme bagging vient de « Boostrap Aggregating ». Il consiste à agréger des modèles, chacun ayant été créé sur un sous-ensemble des données.
À partir du dataset d’apprentissage, plusieurs sous-datasets seront créés aléatoirement. Il s’agit d’un tirage avec remise, donc une même donnée peut se retrouver dans plusieurs sous-datasets. À l’inverse, rien n’impose que toutes les données aient été sélectionnées au moins une fois.
En statistique, le bootstrap est une technique consistant à prendre aléatoirement des sous-ensembles...