
Fonctionnement d'une application web
Introduction
Le World Wide Web, ou plus simplement le Web, est un système de consultation de l’information reposant sur plusieurs éléments : le principe d’hypertexte (ou hyperlien), les URL (Uniform Resource Locator), le protocole de communication HTTP (HyperText Transfer Protocol) et le langage informatique nommé HTML (HyperText Markup Language). La communication sur le Web s’effectue sur un mode de transmission client-serveur.
Tim Berners-Lee est l’inventeur du Web tel que nous le connaissons aujourd’hui. Travaillant au CERN, l’Organisation européenne pour la recherche nucléaire, dans les années 1980, il proposa un projet permettant d’échanger de l’information de manière plus efficace. Les ordinateurs étaient déjà interconnectés entre eux à cette époque, mais il était difficile de trouver une information ou un document présent sur le réseau.
Avant d’aborder les aspects techniques de la sécurité des applications web, il est important de bien comprendre le fonctionnement du Web, car la présence de vulnérabilités est généralement le résultat d’une méconnaissance de ces mécanismes. De plus, l’exploitation de ces faiblesses, ainsi que leurs protections, s’appuie tout autant sur ces mêmes mécanismes....
Le modèle client-serveur
Le modèle client-serveur est un mode de transmission de l’information entre deux entités. La première entité, le client, émet des requêtes vers le serveur. Le serveur, quant à lui, attend des requêtes provenant des clients, les traite et y répond.

Lorsqu’un internaute consulte une page web, le client, généralement un navigateur internet, va effectuer une requête au serveur hébergeant la page demandée. Le serveur traite la demande, puis envoie sa réponse au client. Ensuite, le client interprète cette réponse et affiche le résultat à l’utilisateur.
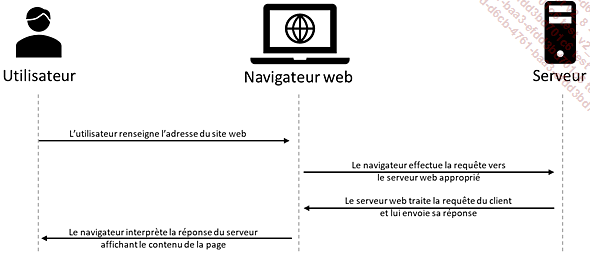
En réalité, Il n’y a pas qu’une seule requête envoyée pour afficher le contenu d’une page web, mais plutôt une requête pour chaque ressource présente sur la page. Une ressource peut être la page elle-même, une image, une vidéo, un fichier audio, etc.
1. Le navigateur web
Le navigateur web est un logiciel qui permet de consulter les informations présentes sur le Web. Il est souvent installé par défaut sur les ordinateurs des utilisateurs : Edge pour le système d’exploitation Microsoft Windows, Firefox pour le système Ubuntu (une distribution Linux) ou encore Safari pour MacOS par exemple. Bien sûr, rien n’interdit...
Le principe d’hypertexte
Derrière ce nom un peu barbare se cache la possibilité de naviguer de document en document, qu’ils soient présents sur le même site web ou non, grâce à des liens cliquables.

Un lien hypertexte (ou hyperlien, ou plus simplement, lien) est donc une manière d’accéder à un document qui peut être hébergé sur n’importe quel serveur. Mais comment localiser l’emplacement du document que l’utilisateur souhaite consulter ? Cette problématique est résolue par la notion d’adresse web ou plus exactement d’URL.
Le principe d’hypertexte a été inventé par Ted Nelson dans les années 1960 dans le cadre du projet Xanadu. Ce projet avait pour but de partager des données informatiques de façon instantanée tout en respectant le principe de droit d’auteur et de suivi de modifications. Tim Berners-Lee a donc repris ce travail en l’adaptant à son projet pour en faire des hyperliens, mais l’amputant au passage des deux derniers principes.
Les Uniform Resource Locator (URL)
Les URL (Uniform Resource Locator) sont des chaînes de caractères qui permettent d’identifier et de localiser un document (ou plus généralement, une ressource) présent sur la toile. Un hyperlien référence une URL permettant ainsi de connaître la destination à atteindre lorsque l’utilisateur clique sur celui-ci. Les navigateurs indiquent, généralement en bas à gauche de la fenêtre, l’URL de destination lors du survol de l’hyperlien avec la souris.
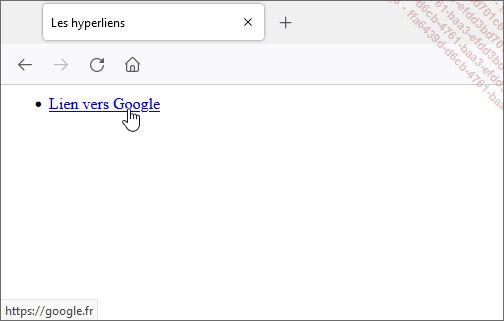
Cela facilite grandement la consultation de documents puisque cela permet de naviguer de document en document. Il est également possible de créer un document listant une multitude de documents comme le ferait une table des matières par exemple.
La syntaxe d’une URL
Une URL possède une syntaxe spécifique qui peut être décomposée de la façon suivante :

-
Le protocole : spécifie le protocole qui sera utilisé afin d’accéder à la ressource. Il existe plusieurs protocoles, mais le principal protocole du Web est le protocole HTTP (et sa version sécurisée...
Le langage HTML
Le langage HTML est un langage de balisage qui permet de définir la structure du contenu d’une page web. La version actuellement utilisée est le HTML5.
1. Les balises HTML
Syntaxiquement, une balise HTML possède une balise dite ouvrante, située à gauche du contenu et une autre dite fermante à droite, à laquelle le caractère slash (/) est également ajouté. Elles sont facilement reconnaissables, car entourées de chevrons. Une balise permet de définir le texte qu’elles encadrent :
<balise>Du texte</balise> Par exemple, pour indiquer qu’un texte doit apparaître en gras au sein de la page, la balise <b></b> (pour bold) est utilisée.
Ceci est du texte dont le mot <b>gras</b> s'affichera en gras. Lorsque l’utilisateur consulte la page, le navigateur interprète le code HTML et affiche le texte de la façon désirée.
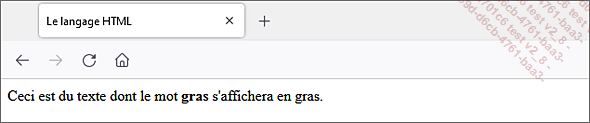
Les balises ne sont pas visibles lors de la consultation des pages web, car le navigateur les interprète et applique leurs effets. Il existe une seconde syntaxe pour certaines balises qui sont composées uniquement d’une balise ouvrante.
<balise> C’est le cas par exemple de la balise <hr>, permettant d’afficher une barre horizontale sur la page.
Ceci est une barre horizontale :
<hr> Le navigateur...
Le protocole HTTP
Le protocole HTTP permet à un client web et à un serveur web d’échanger de l’information de manière standardisée. Plus exactement, il décrit comment les données sont échangées entre ces deux entités.
La version actuellement utilisée est la version 1.1 ainsi que la version 2.0 (utilisée par 35 % des sites web selon le site W3tech, https://w3techs.com/technologies/details/ce-http2). À noter qu’une version 3 existe également. Le protocole ne repose plus sur TCP, mais sur le protocole QUIC. Son adoption est de 27 %, toujours selon W3tech (https://w3techs.com/technologies/details/ce-http3).
1. Anatomie d’une requête HTTP
Une requête HTTP va permettre au client de demander au serveur un document afin de le consulter ou d’effectuer une action. Elle se présente sous la forme suivante :
METHODE URI VERSION_HTTP
En-tête: valeur
En-tête: valeur
...
Contenu de la requête (si nécessaire) a. Les méthodes HTTP
Le protocole supporte plusieurs méthodes (appelées également verbes) permettant de spécifier l’action que souhaite effectuer le client. Les deux principales méthodes sont :
-
GET : permet de demander/récupérer une ressource.
-
POST : contrairement à GET, POST est fait pour créer ou modifier une ressource. La ressource peut être un profil utilisateur dont son propriétaire souhaite y changer une information, l’ajout d’un article dans un panier, etc.
Il existe également d’autres méthodes utilisées dans des contextes spécifiques ou alors qui sont obsolètes :
-
HEAD : cette méthode ne retourne seulement que les informations (les en-têtes HTTP) concernant la ressource, mais, sans retourner la ressource proprement dite.
-
TRACE : utilisée à des fins de diagnostic, elle demande au serveur de retourner ce que vient de lui envoyer le client. Elle est toujours supportée par le protocole, mais les clients et serveurs en limitent ou interdisent son utilisation.
-
OPTIONS : permet au client de demander des informations supplémentaires concernant l’accès à une ressource.
-
CONNECT : utilisée dans...
Le mode développeur du navigateur web
Les principaux navigateurs intègrent un ensemble d’outils destinés aux développeurs. Grâce à ces outils, il est possible pour l’utilisateur de visualiser le code HTML de la page visitée ou encore d’analyser les requêtes et les réponses HTTP effectuées.
Sous Google Chrome, allez dans le menu en haut à droite de la fenêtre représenté par trois points alignés verticalement, puis cliquez sur Plus d’outils et enfin sur Outils de développement. Il est également possible d’utiliser le raccourci-clavier [F12].
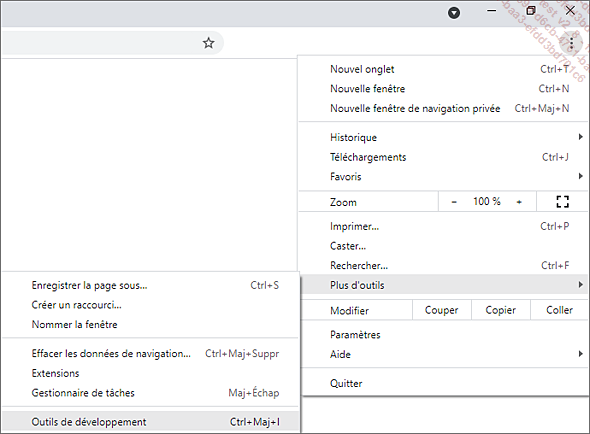
La majorité des navigateurs proposent des outils équivalents, il n’y a donc aucun problème à utiliser un autre navigateur que Google Chrome.
Les outils de développement s’ouvrent dans un nouveau volet. Ils proposent plusieurs onglets dont voici les principaux :
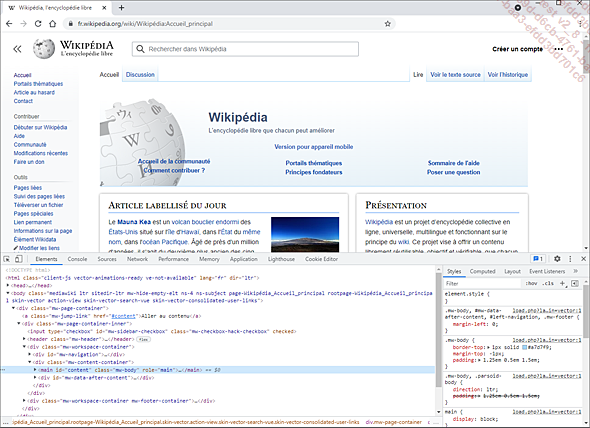
Voici une description des onglets les plus intéressants :
-
Elements : permet de consulter le code source de la page interprétée par le navigateur.
-
Source : liste l’ensemble des ressources utilisées par la page web visitée.
-
Network : affiche les requêtes et les réponses HTTP effectuées lors de la consultation de la page web.
-
Application : donne des informations sur les informations stockées...