
Installation et contexte des outils utilisés
Introduction
Nous abordons à présent les aspects concrets du traitement du langage naturel en utilisant Python et les différents outils relatifs à ce langage.
Bien sûr, nous parlerons de NLTK, de spaCy, de Gensim et de scikit-learn. Nous verrons comment installer ces outils et, concrètement, comment et pourquoi commencer à les utiliser.
Préalablement, nous évoquerons également les bibliothèques NumPy et pandas. Les structures de données offertes par ces deux bibliothèques sont utilisées très fréquemment en Machine Learning, il faut donc en parler.
Nous commencerons par aborder la solution Jupyter qui peut être une bonne façon de travailler en NLP et plus généralement en Machine Learning. En tout état de cause, Jupyter est utilisé quotidiennement dans le monde de la science des données.
Jupyter, méthodologie intéressante
1. Propos
Utiliser Jupyter consiste en la manipulation de notebooks (autrement dit, des carnets de notes) qui autorisent l’utilisateur à exécuter son programme pas à pas, cellule de notebook après cellule de notebook. Cet outil est particulièrement utilisé dans l’univers de la science des données, de l’apprentissage automatique et donc du traitement automatique du langage naturel.
Notons que ce carnet de notes, qui sera ici relatif à du NLP, s’exécute comme un site web local, dans le navigateur web.
Les notebooks Jupyter constituent donc un environnement interactif de développement et de documentation qui permettent d’exécuter du code, de visualiser des résultats, d’écrire du texte et d’intégrer des images ainsi que des graphiques, le tout dans un seul document.
Bien sûr, il n’y a aucune obligation d’utilisation ; il est tout à fait possible et fonctionnel de faire du NLP avec la méthodologie habituelle en Python : projet avec des fichiers d’extension .py, exécution en ligne de commande, utilisation d’environnements virtuels, etc.
2. Installation de Jupyter
L’installation de Jupyter est plutôt classique : on utilise en général le gestionnaire de paquets Python, à savoir pip. Toutefois...
Les bibliothèques NumPy et pandas
Abordons rapidement les deux bibliothèques Python NumPy et pandas, systématiquement utilisées en sciences des données, en Machine Learning et en particulier en NLP. Nous en profiterons pour donner un petit exemple impliquant ces deux modules.
1. NumPy
Le module NumPy est une bibliothèque en Python qui prend en charge les tableaux multidimensionnels ainsi qu’une vaste collection de fonctions mathématiques pour manipuler ces tableaux. Les tableaux NumPy, également appelés ndarray, sont particulièrement efficaces en matière de stockage et de traitement des données ; NumPy est largement utilisé pour le calcul scientifique, le traitement d’images, la manipulation de données et, bien sûr, le Machine Learning.
2. pandas
Le module pandas est une bibliothèque en Python qui offre des structures de données puissantes et faciles à utiliser, notamment les dataframes. Ces derniers consistent en des tableaux de données à deux dimensions, avec des étiquettes de lignes et de colonnes, similaires à une feuille de calcul Excel ou à une table SQL. pandas est idéal pour la manipulation, le nettoyage et l’analyse de données, ce qui en fait sans aucun doute une bibliothèque indispensable en science des données.
3. Exemple illustrant NumPy et pandas
Supposons que nous ayons un jeu de données fictif représentant les ventes mensuelles de deux livres des Éditions ENI, le livre A et le livre B, sur une période de six mois. Nous allons utiliser NumPy pour calculer la somme des ventes de chaque produit, et pandas pour créer un dataframe à partir de ces données.
Comme précédemment, nous allons utiliser un notebook Jupyter.
Il faut d’abord s’assurer que NumPy et pandas sont installés en local ou au sein d’un environnement virtuel courant. Au besoin, les commandes suivantes peuvent être exécutées :
pip install numpy
pip install pandas Commençons par créer un nouveau notebook Jupyter, Python, nommé « Ch402 numpy & pandas.ipynb ».
a. Première cellule
On crée une première cellule dans ce notebook, pour déclarer les deux modules :
import...spaCy
1. Introduction
spaCy est une bibliothèque de traitement du langage naturel en open source, codée principalement en Python, dont la première version a été publiée en 2015. Ses principaux développeurs sont Matthew Honnibal et Ines Montani. Principalement codée en Python, elle est fournie avec une collection de modèles linguistiques, un par langue supportée.
Les modèles linguistiques de spaCy forment un ensemble de fichiers pré-entraînés qui permettent à la bibliothèque de traiter le langage naturel dans une langue spécifique. Ces modèles contiennent des informations telles que les règles de tokenisation, les vecteurs de mots, les règles d’étiquetage grammatical, les modèles de reconnaissance des entités nommées ainsi que les modèles de dépendance syntaxique. Et ceci, pour chaque langue (chaque fichier).
Par exemple, « fr_core_news_sm » est un modèle avec des capacités de tokenisation, lemmatisation, étiquetage grammatical et reconnaissance d’entités nommées, pour le français.
La documentation en ligne de ce modèle linguistique se trouve à cette adresse :
Le suffixe « sm » à la fin du nom du modèle désigne la version légère de ce dernier. Le modèle est effectivement, en général, disponible en trois tailles différentes, indiquant le niveau de performance et sa taille :
-
sm (small) : modèle léger, rapide à charger, mais avec une précision légèrement réduite ;
-
md (medium) : modèle moyen, offrant un meilleur équilibre entre précision et taille ;
-
lg (large) : modèle lourd, offrant la meilleure précision, mais avec une taille plus importante.
Avant d’expliquer comment installer spaCy et de prendre un premier exemple d’utilisation, considérons les similarités et les différences entre spaCy et NLTK, autre bibliothèque que nous aborderons prochainement dans ce chapitre.
2. spaCy et NLTK
spaCy et NLTK sont, par nature, très semblables. Raison supplémentaire pour s’arrêter un instant...
NLTK
1. Introduction
La bibliothèque NLTK (Natural Language Toolkit), comme évoqué précédemment, a certes été pensée et développée avant tout pour la langue anglaise, et c’est d’ailleurs vers cette langue que la plupart des fonctionnalités sont orientées, mais NLTK offre également un support intéressant (bien que non exhaustif) pour d’autres langues, dont le français.
La bibliothèque a été développée avec des versions régulières depuis 2001. Les développeurs principaux sont Steven Bird et Edward Loper.
2. Procédure d’installation de NLTK
Comme habituellement, l’installation proprement dite de la bibliothèque est très simple avec l’outil pip :
pip install nltk Toutefois, comme avec spaCy, certains éléments linguistiques devront être téléchargés pour pouvoir travailler. Nous allons le voir dans la section suivante.
3. Première utilisation de NLTK
a. Première cellule
Pour commencer, on crée un notebook Jupyter dédié : « Ch404 NLTK.ipynb ».
On importe ensuite NLTK et on ouvre la fenêtre de gestion des différents packages NLTK :
import nltk
nltk.download() La seconde ligne nltk.download() permet l’ouverture de la fenêtre suivante :
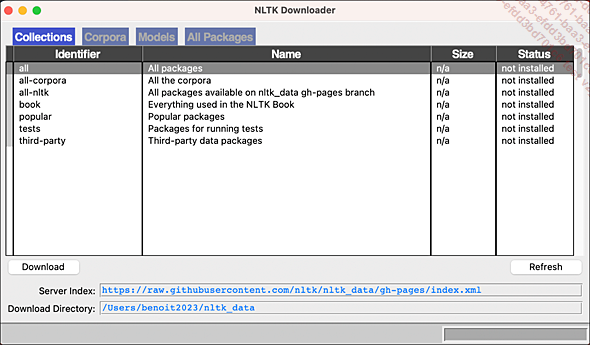
Illustration 4
Ce petit utilitaire permet de choisir les packages qui vous intéressent. Vous pouvez aussi télécharger tout ce qui est proposé. Ici, nous n’allons rien installer. Fermez la fenêtre car nous allons installer ce dont nous avons besoin différemment.
b. Deuxième cellule
Avec NLTK, les ressources ne sont pas téléchargées...
Gensim
1. Introduction
Gensim est une bibliothèque open source conçue pour la création, l’exploration et la mise en œuvre de modèles de traitement de texte et de modèles de représentation de texte dans Python. Elle se distingue par sa capacité à traiter de grandes quantités de texte pour extraire des structures sémantiques sous-jacentes et à créer des modèles vectoriels pour représenter les documents et les mots dans un espace vectoriel continu.
 , en tant
que réponse à la nécessité d’avoir
des outils plus efficaces pour le traitement automatique du langage
naturel. L’objectif principal de Gensim est de fournir des méthodes
de modélisation de texte avancées, notamment la
création de représentations vectorielles de mots
et de documents (comme Word2Vec ou Doc2Vec) et la détection
de sujets (comme LDA, Latent Dirichlet Allocation).
, en tant
que réponse à la nécessité d’avoir
des outils plus efficaces pour le traitement automatique du langage
naturel. L’objectif principal de Gensim est de fournir des méthodes
de modélisation de texte avancées, notamment la
création de représentations vectorielles de mots
et de documents (comme Word2Vec ou Doc2Vec) et la détection
de sujets (comme LDA, Latent Dirichlet Allocation).2. Installation de Gensim
Pour installer Gensim, comme habituellement, on utilise l’outil pip :
pip install gensim 3. Exemple d’utilisation de Gensim
a. Première et deuxième cellules
On crée un notebook dédié, nommé « Ch405 Gensim.ipynb ».
On définit tous les imports et téléchargements dont nous aurons besoin :
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from gensim import corpora
from gensim.models import LdaModel
nltk.download('punkt')
# Télécharger les stopwords anglais de NLTK
nltk.download('stopwords') b. Troisième cellule
Le but ici est de créer un jeu de documents, en l’occurrence des phrases, qui parlent essentiellement de cyclisme ou de cinéma. Et ceci, si possible de manière disjointe, pour éventuellement obtenir deux thématiques claires et distinctes :
# Exemple de phrases sur le cyclisme...scikit-learn
1. Introduction
scikit-learn est une bibliothèque open source très populaire et largement utilisée pour le Machine Learning en Python. Développée par David Cournapeau à partir de 2007, elle offre une gamme étendue d’algorithmes, de fonctions et d’outils pour le prétraitement des données, la création de modèles, l’évaluation de la performance, la sélection de caractéristiques, etc. Contrairement aux bibliothèques précédentes, elle n’est pas spécifique au TALN mais à l’apprentissage automatique (Machine Learning) en général.
2. Installation
Comme d’habitude, on utilise le gestionnaire de paquets pip pour installer scikit-learn :
pip install scikit-learn 3. Première utilisation de scikit-learn
a. Première cellule
On crée un notebook intitulé « Ch406 Scikit-Learn.ipynb ».
On déclare tous les imports dont nous aurons besoin :
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score b. Deuxième cellule
scikit-learn contient des jeux de données utilisables d’emblée pour faire de l’apprentissage automatique. L’un des plus connus est celui relatif à l’iris...
Conclusion
À travers ce chapitre, nous avons survolé NLTK, spaCy, Gensim et scikit-learn, sans oublier Jupyter. Cela nous a permis de situer chacun de ces outils, et surtout de commencer à les utiliser. Nous allons à présent dérouler les grandes thématiques du traitement automatique du langage naturel, en proposant des exemples en Python pour y répondre.