
Aller plus loin avec Debian
Installation de logiciels sous Debian
1. Dpkg et APT
a. Utilisation de Dpkg
Dpkg est le gestionnaire de paquets de « bas niveau » qui permet de gérer les paquets sous Debian. Ce programme est disponible par défaut sous Debian et il est accessible à partir de la commande dpkg depuis un shell.
Cette commande dispose de plusieurs options, notamment l’option -i (pour install - en français, installer) qui permet d’installer un ou plusieurs paquets dont les noms de fichiers correspondant aux paquets sont passés en arguments.
Par exemple, la ligne de commande suivante vous permet d’installer les paquets fictifs paquet1.deb, paquet2.deb et paquet3.deb.
dpkg -i paquet1.deb paquet2.deb paquet3.deb Il est également possible de supprimer un ou plusieurs paquets dont les noms sont passés en arguments grâce à l’option -r (pour remove - en français, supprimer).
L’installation et la suppression de paquets sont accessibles depuis le compte root ou à l’aide de la commande sudo.
Pour lister les paquets installés sur votre système, vous pourrez utiliser l’option -l. L’utilisation de cette option permet également d’obtenir des informations sur l’état des paquets connus par le système.
Ci-dessous, voici un extrait de la sortie de la commande dpkg -l qui permet de lister les paquets.
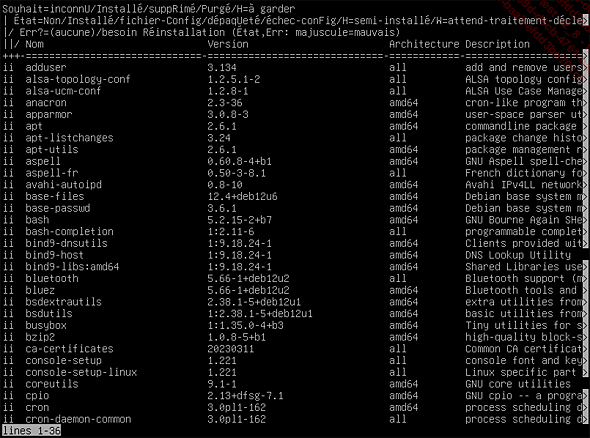
Figure 1 : Capture d’écran de la sortie de commande dpkg pour lister les paquets
L’utilisation de Dpkg pourra s’avérer utile lorsque vous avez obtenu un paquet au format .deb que vous souhaitez installer. Il pourra également être nécessaire pour résoudre des problèmes liés aux paquets installés.
Bien que cette commande dispose de nombreuses options utiles pour gérer les paquets sous Debian, son utilisation dans la gestion courante des paquets est contraignante. En effet, dans le cas où l’installation d’un paquet nécessite une ou plusieurs dépendances, vous devrez gérer manuellement ces dépendances en installant les paquets...
Les utilisateurs et les groupes
1. Notions sur la gestion des utilisateurs sous Linux
On distingue principalement quatre types d’utilisateurs sous Linux, le super-utilisateur, les utilisateurs réservés au système, les utilisateurs applicatifs, ainsi que les utilisateurs réguliers.
Les utilisateurs réservés au système sont créés et gérés par le système. Quant aux utilisateurs applicatifs, ils sont généralement créés lors de l’installation des différents logiciels. Le super-utilisateur est défini par le compte d’utilisateur root, c’est l’utilisateur qui possède les droits les plus élevés sur le système. Enfin, les utilisateurs réguliers correspondent aux différents comptes des utilisateurs réels.
Chaque utilisateur est identifié par un nom unique qui leur permet de s’authentifier sur un système afin d’ouvrir une session. Ce nom d’utilisateur est sensible à la casse, ce qui signifie que le système distinguera une majuscule d’une minuscule. Un numéro unique, appelé UID pour User Identifier (en français, identifiant d’utilisateur), est également associé à chaque utilisateur lors de sa création.
Lorsque l’on souhaite rassembler les utilisateurs selon différents critères, nous pouvons utiliser des groupes d’utilisateurs. Ils sont également identifiés par un nom unique, sensible à la casse, ainsi qu’un numéro unique, appelé GID pour Group Identifier (en français, identifiant de groupe). En regroupant les utilisateurs qui partagent les mêmes rôles, vous pourrez simplifier la gestion des droits et des permissions.
2. Lister les utilisateurs et les groupes
Sous Linux, les utilisateurs et les groupes sont stockés respectivement dans les fichiers de texte brut /etc/passwd et /etc/group que vous pouvez consulter simplement avec une commande de visualisation de texte, tel que cat. Toutefois, il existe de nombreuses commandes qui vous seront utiles si vous souhaitez lister les informations relatives aux utilisateurs et aux groupes sur votre système.
La commande users
Cette commande permet d’afficher la liste des utilisateurs connectés sur le système....
Les droits et les permissions
Les permissions permettent de définir les droits des utilisateurs et des groupes sous Linux. On retrouve différentes commandes que nous allons vous présenter afin de lister les permissions et de gérer les droits attribués aux utilisateurs et aux groupes.
1. Notions sur les permissions
Afin de lister les permissions et les propriétaires d’un fichier ou d’un répertoire, une méthode courante consiste à utiliser la commande ls qui vous a été présentée dans le chapitre précédent (cf. chapitre Débuter avec le shell sous Linux - Naviguer en ligne de commande). En effet, lorsque vous utilisez la commande ls, l’option -l vous permettra également d’afficher les permissions définies pour un fichier.
Par exemple, la ligne de commande suivante permet d’afficher les permissions pour le fichier /usr/bin/apt.
ls -l /usr/bin/apt En sortie de la commande, vous obtenez le résultat suivant :
-rwxr-xr-x 1 root root 18752 25 mai 2023 /usr/bin/apt Si vous souhaitez afficher les permissions pour répertoire, vous devrez utiliser l’option -d également.
Par exemple, la ligne de commande suivante permet de lister les permissions pour le répertoire /usr/bin.
ls -l -d /usr/bin En sortie de la commande, vous obtenez le résultat suivant :
drwxr-xr-x 2 root root 28672 27 nov. 16:50 /usr/bin Le schéma ci-dessous permet d’illustrer l’emplacement correspondant aux permissions et aux propriétaires dans l’affichage du résultat de la commande précédente.
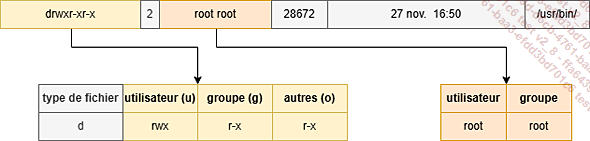
Figure 13 : Représentation des permissions et des propriétaires d’un répertoire
Ce schéma permet de mettre en évidence les deux blocs qui permettent d’afficher les permissions et les droits des utilisateurs et des groupes.
Le premier bloc (en jaune) permet d’afficher les permissions des utilisateurs, des groupes et des autres utilisateurs. Le second (en orange) permet d’afficher les utilisateurs et les groupes propriétaires.
On distingue trois types de permissions primaires sous Linux, et qui sont également représentés dans ce schéma. Il s’agit des permissions pour la lecture (r), l’écriture (w) et l’exécution (x).
Le tableau...
Les processus
1. Notions sur les processus
a. Qu’est-ce qu’un processus ?
On appelle processus l’instance d’un programme en cours d’exécution sur le système. Ils sont identifiés par un identifiant de processus (ou PID, pour Process Identifier) qui permet de les distinguer.
Chaque processus évolue dans son propre environnement d’exécution, toutefois ils sont exécutés de manière hiérarchique sur le système. Ainsi, chaque processus pourra avoir un ou plusieurs processus enfants, et aura forcément un processus parent qui sera identifié par un identifiant de processus parent (ou PPID, pour Parent PID).
On distingue deux grandes catégories de processus, les processus système et les processus du noyau.
À la tête des processus système, on retrouve systemd. C’est le premier processus qui est lancé au démarrage du système. En tant que premier processus exécuté, son PID est égal à 1.
À la tête des processus du noyau, on retrouve kthreadd. C’est le second processus qui est lancé au démarrage du système. En tant que second processus exécuté, son PID est égal à 2.
b. Les daemons
Un daemon est un type de programme conçu pour s’exécuter dans un processus d’arrière-plan. Ce type de programme ne nécessite pas d’interaction avec l’utilisateur. Ils s’exécutent généralement au démarrage du système et fonctionnent en permanence jusqu’à leur arrêt prématuré ou jusqu’à l’arrêt du système.
c. Les jobs
Un job, également appelé tâche en français, est un processus initié et géré depuis le shell. En effet, lorsque vous exécutez une commande depuis le shell, un processus enfant est créé afin d’exécuter le programme associé à la commande. À la fin de son exécution, le shell vous rend la main avec une invite de commandes qui vous permet d’exécuter une nouvelle commande.
2. Lister les processus
a. La commande ps
Cette commande vous permet d’afficher la liste des processus en cours d’exécution.
Lorsque vous exécutez...
Le stockage
1. Vérifier le stockage
La gestion du stockage est essentielle sous Linux. En effet, il est important de surveiller l’évolution de l’espace disponible afin d’anticiper une saturation au niveau de l’espace de stockage.
Dans cette section, nous allons vous présenter les outils utiles que vous aurez à votre disposition si vous souhaitez vérifier l’état du stockage sur votre serveur de manière ponctuelle.
a. La commande lsblk
Cette commande vous permet de lister les disques connectés à votre serveur.
Par défaut, lorsque vous exécutez la commande lsblk sans arguments, elle vous permettra de lister les disques et les partitions, comme l’illustre la capture d’écran suivante :
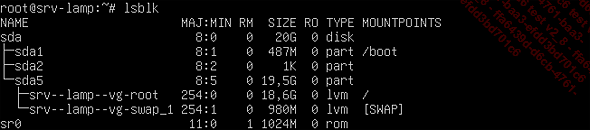
Figure 23 : Capture d’écran de la liste des disques avec lsblk
Vous obtenez ainsi une liste qui comprend des disques (disk) et leur partition (part), ainsi que des volumes logiques (lvm) le cas échéant.
Cette commande propose également des options parmi lesquelles l’option -d qui permet d’afficher uniquement les informations à propos des disques physiques en excluant ainsi les partitions et les volumes logiques.
Par exemple, vous pouvez exécuter la ligne de commande suivante pour lister uniquement les disques physiques.
lsblk -d Ci-dessous, voici un exemple de la sortie de la commande :
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 20G 0 disk
sr0 11:0 1 1024M 0 rom b. La commande df
Cette commande permet de lister de manière concise l’espace utilisé sur un système de fichiers sous Linux.
Par défaut, lorsque vous exécutez la commande df sans arguments, elle vous permettra de lister l’espace occupé pour tous les systèmes de fichiers disponibles, comme l’illustre la capture d’écran suivante.

Figure 24 : Capture d’écran de la sortie par défaut de la commande df
La commande df accepte en argument le répertoire dans un système de fichiers pour lequel vous souhaitez afficher l’état du stockage.
Par exemple, si vous souhaitez lister l’utilisation de l’espace de stockage pour le système de fichiers dans lequel...
Le réseau et les interfaces
1. Vérifier le réseau
Plusieurs commandes sont disponibles sous Linux afin de vous permettre de réaliser des vérifications de l’état du réseau ou de vos accès à certains services.
Dans cette section, nous allons vous présenter les outils utiles que vous aurez à votre disposition si vous souhaitez vérifier l’état du réseau sur votre serveur de manière ponctuelle.
a. La commande ping
Cette commande est utilisée afin de vérifier qu’un hôte est atteignable à travers le réseau.
La syntaxe de cette commande est la suivante :
ping [options] <nom d'hôte ou adresse IP> Par défaut, cette commande envoie un nombre de paquets indéfini. Si vous souhaitez limiter le nombre de paquets envoyés, vous pouvez exécuter la commande ping avec l’option -c suivie du nombre de paquets définis.
Par exemple, la ligne de commande suivante permet d’envoyer quatre paquets à destination de l’hôte avec pour adresse IP 1.1.1.1 :
ping -c 4 1.1.1.1 Ci-dessous, voici un exemple de la sortie de la commande :
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=58 time=5.11 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=58 time=4.89 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=58 time=4.55 ms
64 bytes from 1.1.1.1: icmp_seq=4 ttl=58 time=4.58 ms
--- 1.1.1.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 4.552/4.781/5.107/0.230 ms b. La commande host
Cette commande vous permet d’effectuer une résolution DNS à partir d’un nom ou d’une adresse IP.
La syntaxe de cette commande est la suivante :
host [options] <nom d'hôte ou adresse IP> Par exemple, la ligne de commande suivante permet d’effectuer une résolution DNS pour l’adresse IP 8.8.8.8.
host 8.8.8.8 Ci-dessous, voici un exemple de la sortie de la commande :
8.8.8.8.in-addr.arpa domain name pointer dns.google. Par exemple, la ligne de commande suivante permet d’effectuer une résolution DNS à partir du nom d’hôte www.google.com.
host www.google.com Ci-dessous, voici un exemple de la sortie de la commande :
www.google.com has address 142.251.37.196 ...Activité 1 : Configurer un accès distant
1. Introduction
Dans cette activité, nous allons installer le logiciel OpenSSH server à l’aide du gestionnaire de paquet APT sous Debian. Puis nous allons vérifier le bon fonctionnement du serveur SSH en effectuant une connexion SSH depuis un ordinateur sur le même réseau.
Pour reproduire cette activité, vous devez disposer d’une installation de Debian fonctionnelle. Vous devez également disposer d’un accès à Internet qui vous permettra d’installer les paquets depuis les dépôts officiels de Debian. Enfin, vous devrez exécuter les commandes qui suivent en tant que root ou utiliser un compte d’utilisateur qui dispose des droits d’administration suffisants avec la commande sudo.
2. Installer un serveur SSH
a. Mettre à jour la liste des paquets
Dans un premier temps, nous allons mettre à jour la liste de paquets disponibles dans les dépôts de paquets sous Debian.
Pour cela, vous pouvez suivre les instructions suivantes.
Depuis le terminal de commande, exécutez la ligne de commande suivante en tant que root ou avec la commande sudo.
apt update Cette commande permet de vous assurer que vous allez installer les paquets les plus récents disponibles dans les dépôts de paquets sous Debian.
b. Installer le paquet openssh-server
Une fois la liste des paquets à jour dans APT, nous pouvons installer le paquet qui fournit OpenSSH server.
Pour cela, vous pouvez suivre les instructions suivantes.
Depuis le terminal de commande, exécutez la ligne de commande suivante en tant que root ou avec la commande sudo.
apt install openssh-server Cette commande permet d’installer le paquet openssh-server, ainsi que l’ensemble de ses dépendances comme l’illustre le résumé des actions dans la capture d’écran suivante :
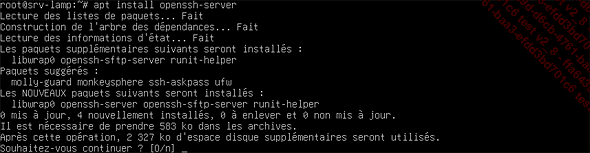
Figure 33 : Capture d’écran du résultat de la commande apt install openssh-server
La commande apt vous proposera un prompt qui vous permettra de confirmer votre choix de poursuivre l’installation de ce paquet. Pour continuer, vous pouvez suivre les instructions suivantes.
Appuyez sur la touche [O] pour Oui (ou [Y] pour Yes).
Puis appuyez sur la touche [Entrée].
L’installation pourra ensuite se poursuivre, notamment avec...
Protéger son serveur sur Internet
1. Utilisation d’un pare-feu
a. Le rôle du pare-feu
Dès lors que vous choisissez d’exposer un serveur sur Internet, il sera nécessaire de le protéger des accès indésirables.
Le pare-feu permet de contrôler les flux réseau qui transitent entre votre serveur et le réseau externe. Votre hébergeur vous proposera généralement une solution de pare-feu qui sera installée en amont de votre serveur, afin de bloquer les requêtes non sollicitées avant de l’atteindre. Toutefois, certaines offres ne disposent pas de ce type de solution, ou vous pourriez choisir de renforcer la sécurité en appliquant également des règles de filtrage directement sur votre serveur à l’aide d’un logiciel de pare-feu.
Dans la section suivante, nous allons vous présenter les logiciels de pare-feu les plus courants sous Linux, ainsi que l’installation de l’un de ces logiciels.
b. Les règles de filtrage
Les règles de filtrage permettent de définir dans un pare-feu les actions à appliquer en fonction du trafic réseau.
Elles se caractérisent par :
-
le sens des flux réseau (soit entrant, soit sortant) ;
-
le protocole réseau (TCP et UDP par exemple) ;
-
les adresses IP source et de destination ;
-
les ports source et de destination ;
-
l’action à appliquer (généralement autoriser ou refuser).
Le tableau ci-dessous permet d’illustrer une liste de règles de filtrage que l’on peut retrouver sur un pare-feu.
|
N° |
Direction |
Protocole |
Source (IP) |
Source (Port) |
Destination (IP) |
Destination (Port) |
Action |
|
1 |
Entrant |
TCP |
Tous |
Tous |
192.168.1.52 |
80 |
Autoriser |
|
2 |
Entrant |
TCP |
Tous |
Tous |
192.168.1.52 |
443 |
Autoriser |
|
3 |
Sortant |
Tous |
Tous |
Tous |
Tous |
Tous |
Autoriser |
|
4 |
Entrant |
Tous |
Tous |
Tous |
Tous |
Tous |
Refuser |
Dans un pare-feu, chaque règle dispose d’un numéro qui permettra de définir son ordre de traitement. En effet, le pare-feu parcourt la liste des règles de manière séquentielle afin de décider de l’action à entreprendre en fonction du trafic réseau, jusqu’à atteindre une règle qui lui correspond.
Dans cet exemple, les règles numéro 1 et 2 permettent d’autoriser...