
Les types évolués
Introduction
Les données utilisées dans le contexte des applications ne cessent d’évoluer. Il est donc normal que les serveurs de bases de données évoluent également en proposant des types adaptés à ces nouveaux formats. C’est ce que fait SQL Server en offrant la possibilité de stocker des données aux formats XML et JSON, des données géographiques ainsi qu’une meilleure gestion des documents annexes (image, vidéo, son, document numérisé...) afin de ne pas alourdir le processus de gestion de la base tout en liant les données relationnelles à ces informations stockées directement sur le système de fichiers.
Le format XML
Les données au format XML sont de plus en plus présentes dans l’environnement de travail. Il est donc normal qu’une base de données s’adapte afin d’être en mesure de stocker et de gérer de façon optimale les données définies dans ce format. C’est ce que fait SQL Server en offrant la possibilité de travailler directement avec des données au format XML et de les stocker dans la structure relationnelle d’une table. Étant donné que XML représente avant tout un format d’échange de données, SQL Server propose également les outils nécessaires pour produire un document XML à partir de données relationnelles ou bien au contraire d’intégrer dans les tables relationnelles des données issues d’un document XML.
Il est possible de stocker les informations, soit au format relationnel, soit au format XML. Chaque format possède ses avantages et ses inconvénients.
SQL Server héberge un moteur relationnel pour le stockage et le travail avec les données conservées à ce format. Mais SQL Server propose également de gérer des données au format XML. Ainsi, quel que soit le mode de stockage retenu, SQL Server peut héberger ces données dans leur format natif.
L’objectif de SQL Server est d’être capable de s’adapter au mode de stockage des données en fonction du format avec lequel travaille l’application cliente.
Microsoft Office permet aux utilisateurs de Word, Excel Visio et InfoPath de générer leurs documents au format XML, par l’intermédiaire du format Open XML. C’est maintenant le format par défaut (.docx, .xlsx...), le x représentant XML.
Le schéma ci-dessous illustre le fait que les applications travaillent aussi bien avec des données au format relationnel qu’au format XML.
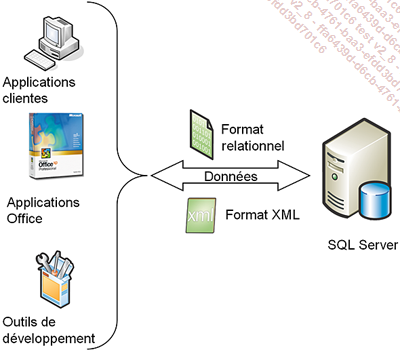
Pour répondre correctement aux différentes demandes, SQL Server a considérablement amélioré sa gestion du format XML.
Choisir un format
Les deux formats ne sont pas en concurrence mais sont complémentaires. Le moteur de base de données doit donc être capable de gérer de façon optimum les données, quel que soit leur format...
Le format JSON
Le format JSON est le format privilégié pour échanger des données dans les applications web et mobiles modernes. Il n’existe pas de type de données particulier en SQL Server. Il faut utiliser une colonne de type NVARCHAR. Cependant, depuis SQL Server 2019, il existe des fonctions permettant de manipuler des données JSON et la clause FOR JSON permettant de donner le résultat d’une requête au format JSON.
1. Les fonctions manipulant du format JSON
a. La création d’une chaîne de caractères respectant le format JSON
Les fonctions JSON_ARRAY() et JSON_OBJECT() permettent de créer une chaîne de caractères représentant respectivement un tableau et un objet au format JSON.
Syntaxes
JSON_ARRAY(valeur, ... [ {NULL|ABSENT} ON NULL ] )
JSON_OBJECT('propriété': valeur, ... [ {NULL|ABSENT} ON NULL ] ) valeur, ...
Suite de valeurs à positionner dans le tableau. Ces valeurs peuvent être des valeurs scalaires (CHAR, VARCHAR, NUMERIC…) mais également des tableaux ou des objets au format JSON.
’propriété’: valeur, ...
Suite de couples nom de propriété associé à une valeur. À nouveau, les valeurs peuvent être de type scalaire, tableau ou objet.
{NULL|ABSENT} ON NULL
Cette option permet d’indiquer le comportement vis-à-vis de NULL. L’option NULL ON NULL permet de transformer l’absence de valeur SQL (NULL) en une absence de valeur au format JSON (null). L’option ABSENT ON NULL permet d’ignorer l’absence de valeur SQL (NULL) dans la valeur produite au format JSON.
Exemples
SELECT JSON_ARRAY(63, 'vis', NULL, 3.14 NULL ON NULL) tableau; 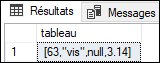
La chaîne de caractères constituée commence par un crochet ouvrant et se termine par un crochet fermant pour indiquer en JSON qu’il s’agit d’un tableau. Entre ces deux crochets, les valeurs se succèdent séparées entre elles par des virgules. L’option NULL ON NULL permet de conserver l’information qu’un NULL était présent dans la liste des valeurs.
SELECT JSON_ARRAY(63, 'vis', NULL, 3.14 ABSENT ON NULL) tableau; 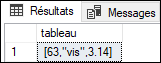
Dans ce second exemple, l’option ABSENT ON NULL fait que le NULL présent parmi...
Le type table value parameter
Avec ce type de paramètre, il est possible d’envoyer un ensemble de données directement à une procédure ou bien à une fonction Transact-SQL. Pour mieux comprendre l’intérêt des table value parameter, il est possible de rapprocher ce type de paramètre à la notion de tableau. Chaque ligne de ce tableau est définie par rapport à un type de données utilisateur. Ces types sont créés par l’intermédiaire de l’instruction CREATE TYPE qui permet maintenant de définir des types TABLE. Chaque champ est fortement typé grâce à l’usage, entre autres, des contraintes d’intégrité lors de la définition du type.
Avec les table value parameter il est possible de gérer un ensemble structuré de données sans qu’il soit nécessaire de créer une table, même temporaire. En ce sens, l’utilisation de ces types permet de gagner en souplesse d’utilisation et parfois même en performance. Cependant, les table value parameter sont toujours des paramètres en lecture seule. Donc, la procédure ou la fonction qui possède un paramètre de ce type ne peut modifier les informations présentes dans ce paramètre.
L’utilisation d’un table value parameter peut se décomposer en trois...
Les structures hiérarchiques
La notion d’organisation hiérarchique se rencontre dans de nombreux domaines dans la vie de tous les jours et la modélisation n’en est pas toujours aisée. C’est par exemple le cas pour un organigramme d’entreprise. SQL Server propose un type de données (hierarchyId) et des méthodes afin de stocker de façon structurée cette hiérarchie. Il est également possible d’optimiser le parcours de cette hiérarchie par l’intermédiaire d’index qui permettent de parcourir rapidement l’arborescence. De plus, SQL Server offre au travers du Transact-SQL des méthodes spécifiques à ce parcours d’arborescence afin de faciliter les extractions de données.
1. Le type de données HierarchyId
Il s’agit d’un type de données spécifique à SQL Server qui peut être utilisé pour modéliser une structure hiérarchique dans une table relationnelle. Les données pourront être extraites de cette table en utilisant les requêtes hiérarchiques.
Cette notion de hiérarchie n’est en aucun cas assimilable à une contrainte d’intégrité ; il est possible de trouver des éléments orphelins c’est-à-dire qui ne sont pas rattachés à l’arborescence définie. Les éléments orphelins peuvent apparaître à la suite de la saisie d’une mauvaise valeur ou à la suite de la suppression de l’élément qui était le supérieur hiérarchique.
Le type hierarchyId offre tout le support nécessaire pour modéliser proprement une hiérarchie dans les tables. Toutefois, le simple fait de définir une colonne de ce type dans une table ne garantit en aucun...
Les données images
Aujourd’hui, les bases de données doivent être en mesure de stocker des données non structurées et c’est ce que propose SQL Server avec son type FILESTREAM. En effet, les documents numériques sont de plus en plus présents dans notre quotidien et aujourd’hui il est courant de travailler avec des photos, des fichiers Word, Excel, des documents scannés… Or, tous ces documents ne peuvent que difficilement trouver leur place dans une base de données relationnelle structurée avec des types de données simples. De plus, ces documents représentent très souvent un volume important. C’est pourquoi, bien souvent, l’une des options suivantes est retenue :
-
Les données structurées sont stockées dans la base de données tandis que les données non structurées (fichiers) sont stockées directement sur le système de fichiers.
-
Les données structurées sont stockées dans une base de données et les données non structurées sont stockées dans une autre base.
-
Toutes les données, structurées ou non, sont stockées dans la base de données.
Les deux premières solutions posent le problème de la liaison entre les différentes données. Comment, par exemple, associer correctement l’image d’un produit à sa référence, sa désignation… et plus particulièrement comment garantir que lors de la suppression d’une image, l’article associé n’existe plus
La troisième solution évite ces problèmes mais pose le problème délicat de la gestion de l’espace disque dans la base de données. De plus, les fichiers de données très volumineux ont tendance à dégrader les performances du moteur de base de données.
Pour essayer de tirer parti des différentes options, SQL Server...
Les données spatiales
Les applications qui travaillent avec des données géographiques sont maintenant nombreuses et elles permettent un repérage plus rapide de l’information, souvent avec comme objectif de dresser un itinéraire. Mais les applications peuvent également utiliser les données géographiques pour obtenir une représentation visuelle des données ou bien pour faire une analyse géographique des données (où sont répartis nos principaux clients ? …).
Les possibilités d’affichage de SQL Server Management Studio étant limitées, il est le plus souvent nécessaire de s’appuyer sur une bibliothèque graphique conséquente comme BingMaps ou Open Street Map pour exploiter au mieux de façon visuelle ces données.
Toutefois, il n’est pas possible de gérer de la même façon les données relatives à un schéma d’une ville ou d’un quartier et celles relatives à un pays. En effet, le chemin pour se rendre de la place de la Concorde à la place de l’Étoile à Paris est infiniment plus court que le trajet à effectuer pour se rendre de Paris à Mayotte. Dans le premier cas, il est possible de considérer que la terre est plate, alors qu’il n’est plus possible de faire cette approximation...
Exercices
1. La mise en place d’une hiérarchie des catégories d’articles
Afin de mieux organiser les catégories, il a été décidé de mettre en place la hiérarchie suivante :
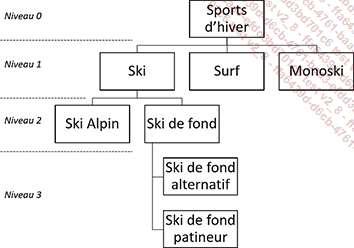
Modifiez la table Categories en conséquence, ajoutez les nouvelles catégories et mettez à jour celles déjà existantes.
2. L’affichage de la hiérarchie des catégories
Affichez les libellés des catégories de niveau 1 :
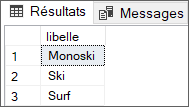
Affichez les libellés des catégories de niveau 1 avec leurs catégories de niveau 2 :
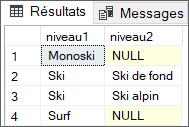
Affichez l’arborescence des libellés de catégories sur les niveaux 1, 2 et 3 :
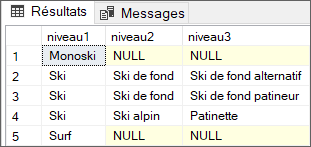
3. L’export des articles au format XML
Nous avons besoin de faire un export des articles proposés à la location au format XML.
Le format attendu est le suivant :
<catalogue>
<article>
<reference>A01</reference>
<designation>Salomon 24X+Z12</designation>
<gamme>EG</gamme>
<categorie>SA</categorie>
</article>
<article>
<reference>A02</reference>
<designation>Salomon 24X+Z12</designation>
<gamme>EG</gamme>...Correction des exercices
1. La mise en place d’une hiérarchie des catégories d’articles
USE Location;
ALTER TABLE Categories ADD hierarchie HIERARCHYID NULL;
GO
INSERT INTO Categories(codeCate, libelle, hierarchie) VALUES('SPH',
'Sports d''hiver', HIERARCHYID::GetRoot());
DECLARE @ski HIERARCHYID = HIERARCHYID::GetRoot().GetDescendant(NULL, NULL);
INSERT INTO Categories(codeCate, libelle, hierarchie) VALUES('SKI',
'Ski', @ski);
DECLARE @surf HIERARCHYID = HIERARCHYID::GetRoot().GetDescendant(@ski, NULL);
UPDATE Categories SET hierarchie = @surf WHERE codeCate = 'SURF';
DECLARE @mono HIERARCHYID = HIERARCHYID::GetRoot().GetDescendant(@surf, NULL);
UPDATE Categories SET hierarchie = @mono WHERE codeCate = 'MONO';
DECLARE @skiFond HIERARCHYID = @ski.GetDescendant(NULL, NULL)
INSERT INTO Categories(codeCate, libelle, hierarchie) VALUES('FOND',
'Ski de fond', @skiFond);
DECLARE @skiAlpin HIERARCHYID = @ski.GetDescendant(@skiFond, NULL);
UPDATE Categories SET hierarchie = @skiAlpin WHERE codeCate = 'SA';
UPDATE Categories SET hierarchie = @skiAlpin.GetDescendant(NULL,
NULL) WHERE codeCate = 'PA';
UPDATE Categories SET hierarchie = @skiFond.GetDescendant(NULL, NULL)
WHERE codeCate LIKE 'FO[AP]...
