
Au cœur de la machine
Présentation du processeur central de l’ordinateur
Les processeurs d’une unité centrale (UC) sont rythmés par un circuit « horloge », possédant aujourd’hui une fréquence variable en fonction d’un compromis efficacité/consommation d’énergie.
Par exemple, le processeur de marque Intel, le CPU (Central Processing Unit) nommé « Core i9-12900KF », possède une fréquence de base de 3,2 gigahertz et monte couramment à 4,55 ou 5,2 GHz.
Un GHz correspond à 1 milliard de cycles par seconde, ce qui est considérable si l’on pense que le courant alternatif en France est de 50 Hz et que l’ouïe humaine ne distingue pas les sons aigus au-dessus de 20 000 Hz (et ne distingue pas les sons graves ayant une fréquence inférieure à 16 Hz).
Depuis les années 2000, il a fallu mettre en place de nouvelles stratégies pour continuer, tous les deux ans, à doubler le nombre de composants sur une même surface de silicium tout en doublant la puissance de la puce en question (ce que l’on nomme souvent la « loi de Moore », même si de nombreux débats ont eu lieu au sujet de cette qualification).
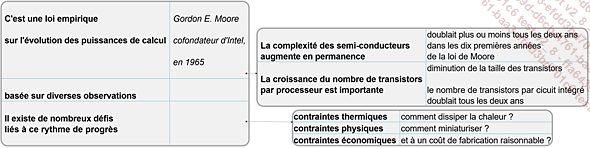
Loi de Moore en bref
On ne peut plus se contenter de miniaturiser les composants et d’augmenter la fréquence....
Fonctionnement du processeur et assembleur
1. Zoom sur une unité centrale de traitement (CPU)
Sur un ou plusieurs cycles, chaque thread effectue une instruction simple avant de passer à l’instruction suivante. Une instruction peut être une addition (ADD), le chargement ou le déchargement d’une valeur (LOAD), un saut vers une instruction qui ne serait pas contiguë (JMP) ou une comparaison entre deux valeurs (CMP) conditionnant un saut éventuel vers une autre instruction. Les langages informatiques à même de décrire (coder) une séquence de ces instructions sont appelés assembleurs. Tous les autres dialectes informatiques sont des surcouches permettant la mise en œuvre de code similaire à celui que produit un assembleur.
La mémoire propre d’un processeur est très restreinte, elle se compose de quelques emplacements de mémoire rapidement accessibles nommés registres (typiquement de 16, 32 ou 64 bits) et de l’adresse de la prochaine instruction à exécuter (dénommée compteur ordinal, pointeur d’instruction, program counter, instruction address register ou instruction pointer, souvent symbolisée par un $ ou par les acronymes PC ou EIP).
Quand l’instruction pointée par le compteur ordinal est déclenchée, c’est tout un cycle qui se lance (dénommé instruction cycle ou fetch-decode-execute cycle). L’étape fetch (aller chercher) permet d’accéder au détail de l’instruction, qui va ensuite être décodée et exécutée sur un certain nombre d’impulsions de l’horloge (clock pulse). On pourra y trouver une lecture ou une écriture (Entrée/Sortie : I/O pour Input/Output) supportée par l’interruption gérant un périphérique comme un clavier ou l’écran, l’invocation de l’unité arithmétique et logique (ALU) pour effectuer des calculs binaires sur des nombres entiers ou l’invocation de la FPU (Floating-Point Unit) qui gère les calculs sur les nombres réels. On les nomme ainsi car le point (.) d’un nombre décimal n’est pas toujours au même endroit (pour vous en convaincre, comparez 100.1 et 3.1416).
Un petit nombre de registres généraux...
Autour du CPU
1. Début de la séquence de démarrage d’un ordinateur
Nous avons déjà identifié l’horloge et nous pouvons imaginer que pour que le processeur puisse démarrer, il faut que certaines instructions de démarrage lui soient accessibles. Souvent, ces instructions se trouvent dans une puce CMOS (Complementary Metal-Oxide Semiconductor) comportant une mémoire « presque » non volatile NVRAM (Non-Volatile Random-Access Memory) qui maintient ces instructions accessibles du fait qu’elle est soutenue par une batterie (typiquement une batterie bouton de 3 V). En fait, fréquemment, le circuit horloge et divers éléments à conserver, comme la date et l’heure, sont également stockés dans une telle puce CMOS.
Au démarrage, les premières instructions exécutées par le processeur sont en général stockées dans ce type de composant. Dans le cadre d’un PC classique, on parle par exemple de BIOS (Basic Input/Output System). Ce programme peut dans de nombreux cas être paramétré par l’utilisateur au travers d’une interface homme-machine relativement rudimentaire que les utilisateurs ont pris l’habitude d’appeler « le BIOS ». Ces interfaces diffèrent d’un fournisseur de carte mère à un autre ; certaines permettent des paramétrages sophistiqués de la machine, d’autres non. On peut par exemple choisir l’ordre de parcours des disques sur lesquels on va chercher le système d’exploitation (qui n’est pas encore lancé à ce stade), déclarer les caractéristiques des disques physiques de la machine, choisir les fréquences de fonctionnement du CPU, configurer un mot de passe d’accès au BIOS, choisir la fréquence de fonctionnement des barrettes mémoires, paramétrer les seuils de température qui vont déclencher le refroidissement du CPU ou du boîtier, etc.
Sur les PC modernes, le BIOS se trouve doté de nombreuses capacités encapsulées dans un microprogramme qui se comporte un peu comme un mini système d’exploitation, nommé UEFI (Unified Extensible Firmware Interface). Pour des raisons de compatibilité...
Les ordinateurs actuels calculent en binaire
Nous calculons en base 10 et les machines calculent en base 2.
Les valeurs binaires (en base 2) manipulées par l’ordinateur, nous sont souvent présentées en hexadécimal (base 16) ou en octal.
Par exemple, dans notre code assembleur, la mention 0x80 désignait l’identifiant en hexadécimal (reconnaissable par le préfixe 0x utilisé dans le langage C et en assembleur) du code noyau de Linux.
Vous verrez donc des codes d’erreur système exprimés en hexadécimal et porter ce préfixe, puisque l’assembleur et le C sont très utilisés pour les couches de code les plus basses.
L’octal est de moins en moins usité, mais dans certains langages ou dans de vieux codes informatiques les conventions utilisées peuvent vous induire en erreur. Par exemple, on y préfixait les nombres avec un « 0 » pour stipuler que c’était de l’octal, donc l’expression 0100 ne signifiait pas 100 en décimal mais 64 en octal. Parfois, on utilisait « \ » comme préfixe de l’octal ce qui aurait donné \100 dans notre exemple.
1. Petites réflexions au sujet de la représentation décimale des entiers (base 10)
En base 10, un entier naturel (positif ou nul) est représenté par une suite de symboles, pris parmi 10 symboles (de 0 à 9) qui représentent les valeurs zéro puis les 9 entiers positifs suivants. Pour mémoire, voici quelques puissances de 10, ceci vu de façon « algorithmique » :
-
10 puissance 0 = 1
-
10 puissance 1 = 1 * 10 = 10
-
10 puissance 2 = 10 * 10 = 100
-
10 puissance 3 = 100 * 10 = 1000
-
10 puissance 4 = 1000 * 10 = 10000…
Par exemple, l’entier 593 (dans notre base 10 habituelle) représente l’addition suivante :
5 x 100 + 9 x 10 +3 x1
C’est-à-dire :
5.102 + 9.101 + 3.100
2. Introduction aux calculs en hexadécimal (base 16)
La représentation hexadécimale est quotidiennement utilisée par les techniciens ou les ingénieurs intervenant sur les réseaux informatiques et leurs applications. Il ne serait pas raisonnable de l’évincer de votre panel de connaissances de base.
La base 16 a de nombreux avantages :...
Encodage des caractères
Quand vous utilisez un éditeur de texte, la ligne de commande, une base de données classique, un tableur, vous manipulez principalement des expressions sous forme textuelle.
Ces expressions comportent des caractères alphabétiques, des représentations des dix chiffres (attention, ce ne sont pas les valeurs que vous manipulez mais le caractère, c’est-à-dire une référence au « dessin » qui les représente), des caractères plus rares comme une barre verticale (|) et enfin des caractères spéciaux, invisibles si vous ne demandez pas à les voir, qui ont la particularité d’agir sur l’aspect du texte quand vous le visualisez à l’écran ou lors d’une édition papier (typiquement le caractère invisible « saut de ligne » pour aller à la ligne ou le caractère « tabulation »).
Les programmes qui manipulent ces données textuelles les interprètent et les stockent en fonction de leurs propres objectifs. Un éditeur de texte vous permet de visualiser les caractères de votre langue, interprète certains caractères spéciaux comme le saut à la ligne ou la tabulation au lieu de vous les montrer (sauf si vous lui demandez explicitement). Un tableur agit de même, sauf dans certaines cellules que vous avez stipulées comme étant numériques, où il interprète la chaîne de caractères représentant des chiffres (ainsi que les caractères plus, moins, virgule ou point) pour reconstituer une valeur numérique, qui est ensuite manipulée et sauvegardée comme telle.
Quand vous ouvrez un fichier d’extension .csv avec un éditeur de texte simple comme Vim, Nano, Notepad++, vous constatez que ce fichier est constitué de lignes de structures similaires qui comportent des caractères, y compris pour les valeurs numériques. La preuve en est que vous pouvez retirer un caractère d’une expression représentant une valeur numérique, sinon nous aurions seulement la possibilité de supprimer l’ensemble de la chaîne ou de ne rien supprimer du tout. Si vous demandez à votre éditeur de vous montrer les caractères...
Systèmes de fichiers
Les données sont stockées (on peut dire « sérialisées ») sur différents supports, typiquement sur des disques durs. Afin de retrouver celles-ci, il faut disposer d’une représentation fiable et normalisée des différents agrégats de données : les fichiers. Comme ceux-ci sont régulièrement mis à jour ou détruits, il a fallu mettre en place différentes stratégies pour répartir efficacement ces données en petites parties, ce qui se concrétise par une partition de celles-ci et la gestion de répertoires les indexant qui permettent de mémoriser l’agencement de toutes ces parties constituantes des divers fichiers. Cette volonté d’une organisation efficace et optimale se concrétise dans la notion de « système de fichiers ».
Remarque préliminaire concernant le démarrage d’un PC : on y trouve un enregistrement particulier, par exemple nommé le MBR, à savoir le Master Boot Record du disque, permettant de charger la partition du disque et de déterminer le secteur de boot de la machine. C’est au travers de cela que l’on pourra invoquer le file system de la machine et donc accéder à nos fichiers.
Les systèmes de fichiers suivants sont très courants (ne pas confondre système de fichiers et format de fichier, ce dernier représentant l’organisation logique interne du fichier) :...
Carte graphique GPU, CUDA et IA
À l’inverse des concepts précédents, nous allons maintenant aborder un élément de configuration bien plus proche de l’utilisateur final et/ou de son poste de travail ou des nouvelles habitudes de traitement de la donnée popularisées par ChatGPT : les cartes graphiques, à savoir les GPU.
Les GPU actuelles sont capables de traiter des quantités massives de données en parallèle, ce qui les rend particulièrement adaptées aux tâches intensives en calcul, telles que l’IA, la simulation scientifique et le rendu vidéo. Les GPU sont également utilisées dans les domaines de la réalité virtuelle et augmentée, où des performances graphiques élevées sont nécessaires pour créer des expériences immersives.
Des GPU puissantes sont utilisées dans le cadre de l’intelligence artificielle (IA), en particulier via des frameworks de développement comme TensorFlow et PyTorch, et ce pour plusieurs raisons :
-
Leur capacité de calcul parallèle. En effet, les GPU sont dotées de milliers de cœurs de traitement parallèle.
-
Leur faculté d’accélération des opérations matricielles (en fait tensorielles), notamment lors de la manipulation des tenseurs (grands tableaux à plusieurs...
Réseaux et communications applicatives
1. Les réseaux locaux, introduction
Au quotidien, nos machines sont souvent reliées à un LAN. Un LAN (Local Area Network) est un réseau local qui relie des appareils, tels que des ordinateurs, des imprimantes et des serveurs, à l’intérieur d’une zone géographique limitée, telle qu’un bâtiment, un bureau ou une maison.
L’objectif d’un réseau local est de permettre la communication et le partage des ressources entre des appareils connectés.
Les principales caractéristiques d’un réseau local sont les suivantes :
-
Zone géographique limitée : les réseaux locaux couvrent une zone relativement petite, comme un seul bâtiment ou un groupe de bâtiments proches.
-
Connexion à haut débit : les réseaux locaux utilisent généralement des connexions à haut débit, telles qu’Ethernet, pour faciliter le transfert rapide de données entre les appareils.
-
Ressources partagées : les appareils d’un réseau local peuvent partager des ressources telles que des imprimantes, des serveurs et des périphériques de stockage. Cela permet une collaboration et une utilisation efficaces des ressources au sein du réseau.
-
Contrôle local : les réseaux locaux sont généralement privés et contrôlés par l’organisation ou la personne qui les a mis en place. Cela permet à l’administrateur du réseau de gérer et de sécuriser le réseau en fonction de ses besoins spécifiques.
Les réseaux locaux sont couramment utilisés dans les foyers, les petites entreprises, les établissements d’enseignement et d’autres environnements, où un réseau localisé suffit à répondre aux besoins de communication et de partage des ressources des utilisateurs.
Les réseaux locaux peuvent avoir différentes topologies, c’est-à-dire que les appareils sont en relation suivant des schémas de relation qui diffèrent.

Comment sont distribuées les machines d’un réseau
Pour acheminer les données d’un expéditeur vers un ou plusieurs destinataires au travers du réseau...