
Fonctionnement d’un ordinateur
Introduction
Ce chapitre a pour vocation de donner au lecteur une vision suffisamment complète et précise des différents éléments constitutifs d’un ordinateur et de leur fonctionnement. Nous entrerons dans les entrailles du matériel et des mécaniques fondamentales implémentées au sein des systèmes d’exploitation modernes pour l’exécution des programmes. Nous parcourrons d’abord les éléments généraux du fonctionnement d’un ordinateur, puis de façon détaillée les comportements les plus fondamentaux, de la gestion de l’exécution des programmes à la gestion de la mémoire virtuelle.
L’architecture matérielle d’un ordinateur
Dans les entrailles d’un ordinateur moderne se cache une symphonie complexe de composants électroniques, chacun jouant un rôle indispensable dans l’exécution des tâches que nous utilisons au quotidien. Derrière la façade familière de l’interface utilisateur et de nos applications favorites se trouve un réseau interconnecté de circuits numériques, orchestrant des milliards d’opérations à chaque seconde. Loin d’être une simple collection de pièces, chaque composant et chaque mécanisme est conçu pour réaliser des fonctions précises et travailler en harmonie avec les autres.
Que ce soit pour afficher des images complexes via la carte graphique, pour sauvegarder des données sur un disque SSD ultrarapide, ou pour optimiser l’utilisation de la mémoire et des ressources CPU, chacun a une place fondamentale dans le fonctionnement global de l’ordinateur.
1. Architecture simplifiée d’un ordinateur moderne
Le schéma présenté sur la figure 3-1 présente les principaux composants fonctionnant ensemble au sein d’un ordinateur. Il met en évidence l’importance du chipset au centre de l’architecture et son rôle dans la mise à disposition du processeur des autres composants. Nous allons détailler l’usage et le fonctionnement de chacun de ces composants et évoquer leur évolution des premiers ordinateurs aux ordinateurs modernes.

Figure 3-1 - L’architecture interne d’un ordinateur
L’architecture matérielle de nombreux ordinateurs a évolué vers une intégration croissante des composants au sein d’une seule puce, le System on Chip (SoC). Les architectures modernes, comme celles des puces ARM, Apple Silicon ou Qualcomm Snapdragon, regroupent désormais sur un même circuit le processeur, le contrôleur mémoire, la carte graphique, et parfois même les interfaces réseau.
Cette évolution rend la frontière physique entre carte mère, chipset et processeur beaucoup plus floue. Cependant, la distinction logique entre ces éléments demeure pleinement valide : chacun conserve son rôle fonctionnel et ses interactions spécifiques...
L’architecture logicielle système
L’architecture logicielle système au sein d’un ordinateur repose sur une hiérarchie de couches, chacune ayant des responsabilités spécifiques et des interfaces définies pour interagir avec les autres niveaux. Au cœur de cette architecture se trouve le noyau (kernel) du système d’exploitation (Operating System), qui gère l’interfaçage entre les logiciels et le matériel, et implémente les mécaniques fondamentales nécessaires au fonctionnement de l’ordinateur.
Le système d’exploitation permet aux applications de fonctionner de manière abstraite, sans avoir à se soucier des détails complexes de la gestion du matériel ou celle des ressources. En surface, les utilisateurs interagissent avec des applications et des interfaces conviviales, tandis qu’en profondeur, le système d’exploitation orchestre la gestion des processus, de la mémoire et des opérations d’entrée/sortie (communication) vers les périphériques (disque dur, carte son, etc.) pour garantir que l’ensemble des composants travaillent en harmonie.
Nous ferons fi ici des considérations historiques pour nous concentrer sur l’architecture logicielle système moderne. Le chapitre Les systèmes d’exploitation présente les systèmes d’exploitation d’un point de vue historique.
Mais commençons par expliquer la différence fondamentale entre le matériel et le logiciel :
-
Le matériel (hardware) désigne les composants physiques et tangibles, comme le processeur, la mémoire, le disque dur et la carte mère, qui permettent de réaliser des opérations et de stocker des données.
-
Le logiciel (software), quant à lui, regroupe les programmes et les couches du système d’exploitation qui donnent des instructions au matériel pour exécuter des tâches spécifiques. Le logiciel est réalisé sous la forme de lignes de codes ou de données binaires et utilise le matériel pour fonctionner. Ensemble, ils forment la base de tout système informatique.
1. Architecture logicielle simplifiée d’un ordinateur moderne
Le schéma présenté...
L’exécution de processus
L’exécution des processus - les programmes - engage plusieurs mécanismes fondamentaux opérés par le système d’exploitation et introduits dans cette section.
1. Le chargement d’un processus en mémoire
Lorsqu’un utilisateur lance un programme ou processus (process en anglais), le noyau du système d’exploitation prend en charge les démarches nécessaires au chargement en mémoire de ce programme pour qu’il puisse s’exécuter. Le noyau réserve un espace dans la mémoire physique (RAM) pour héberger ce programme. Il initialise aussi l’espace de mémoire (virtuelle) du programme et organise les différentes sections, telles que la zone de code (instructions du programme) où le code machine du programme est chargé, la zone de données (variables statiques), ainsi que l’espace réservé à la pile (stack) et au tas (heap) pour les allocations dynamiques.
Nous utiliserons parfois le terme mémoire virtuelle d’ores et déjà dans cette section par souci de rigueur technique alors que nous n’avons pas encore introduit cette notion ni les mécaniques attenantes. Le lecteur peut ignorer pour l’instant cette subtilité qui sera bientôt expliquée et considérer qu’on parle simplement de la mémoire (RAM) ou consulter à l’avance la section La mémoire virtuelle.

Figure 3-6 - Les composants impliqués dans le chargement des processus en mémoire
La figure 3-6 présente les composants impliqués dans le chargement des processus en mémoire. La mémoire est représentée par la zone à droite depuis sa première adresse 0x00... à la dernière 0xFF... en hexadécimal (cette valeur étant ici purement théorique puisqu’aucun ordinateur au monde n’a suffisamment de RAM pur arriver au dernier nombre hexadécimal de l’espace d’adressage). Le noyau qui réalise ces opérations ainsi que le système de fichiers sur lequel réside le programme sont aussi indiqués.
La figure 3-7 présente le processus de chargement du programme et l’organisation résultante (layout) de l’espace...
La pile d’appels
Le principe d’un appel de fonction implique plusieurs étapes impliquant des opérations de manipulation de la pile en mémoire et des registres du processeur pour assurer le bon déroulement du programme. Nous reparlerons des appels de fonction dans le contexte de la programmation dans le chapitre La programmation à la section Les langages procéduraux.
1. L’exécution de fonctions
Lorsqu’une fonction est appelée, un cadre de fonction (function frame) est créé et poussé dans la pile d’appels (call stack) pour stocker les informations relatives à cet appel. Cette pile d’appels permet de suivre l’exécution des fonctions imbriquées et de garantir une exécution cohérente du programme lors du retour d’un appel de fonction en continuant l’exécution à l’endroit d’où elle a été appelée.
Le cadre de fonction est une section de la pile qui contient les informations spécifiques à un appel de fonction. Il inclut notamment :
-
Les paramètres de la fonction : il s’agit des arguments passés à la fonction, nécessaires pour que la fonction appelante puisse passer ces valeurs à la fonction appelée.
-
Les variables locales : toutes les variables déclarées à l’intérieur de la fonction sont stockées dans cette zone. Il y a ainsi au sein du cadre de fonction une zone mémoire allouée aux variables locales de la fonction.
-
L’adresse de retour : c’est l’emplacement mémoire (adresse) correspondant à la ligne de code du programme où l’exécution doit reprendre une fois la fonction exécutée, c’est-à-dire l’instruction suivante de la fonction appelante.
-
Le pointeur de base précédent : avant d’installer un nouveau cadre de fonction, le contenu du registre servant de pointeur de base est sauvegardé sur la pile. Cela permet de restaurer le contexte du cadre précédent lors du retour de fonction.
-
Le pointeur de pile précédent : bien que rarement utilisé explicitement (puisqu’il correspond au pointeur de base actuel), le contenu du pointeur de pile est également...
L’allocation dynamique de mémoire
La seconde mécanique fondamentale qu’il est important de comprendre en détail dans le cadre de l’exécution des processus au sein d’un ordinateur est l’allocation dynamique de mémoire, qui repose sur l’usage du tas (heap).
L’allocation dynamique de mémoire permet de réserver de la mémoire pendant l’exécution d’un programme, plutôt qu’au moment de la compilation. Cela est nécessaire lorsque la quantité de mémoire requise n’est pas connue à l’avance ou peut varier en fonction des conditions d’exécution, comme le traitement de fichiers de taille variable ou la gestion de structures de données extensibles (listes, tableaux dynamiques, etc.). Comme nous l’avons vu, les variables connues et de taille prédéfinie au sein du programme sont allouées dans une zone spécifique de la mémoire du processus (data).
Ensuite, les paramètres et variables locales de fonctions, elles aussi connues et de taille prédéfinie, sont gérées sur la pile. Mais les programmes peuvent avoir besoin de données dynamiques et il fallut trouver un moyen de les représenter en mémoire. C’est ici qu’interviennent le tas et l’allocation dynamique de mémoire.
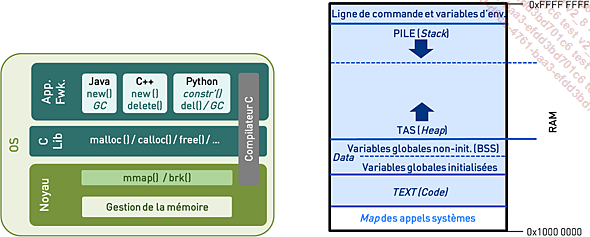
Figure 3-10 - Retour sur le tas (heap)
1. L’allocation de mémoire
Le tas permet d’allouer de la mémoire de façon dynamique pour des structures dont la taille peut varier ou n’est pas connue à l’avance. Cette mémoire est allouée au...
La mémoire virtuelle
La mémoire virtuelle est une technique utilisée par les systèmes d’exploitation pour gérer de manière efficace l’accès à la mémoire. Elle permet à chaque programme de croire qu’il dispose de sa propre grande quantité de mémoire, appelée mémoire virtuelle, indépendamment de la taille réelle de la mémoire physique disponible (RAM). La mémoire virtuelle permet également de « faire croire » à chaque processus qu’il est seul sur l’ordinateur, lui permettant ainsi de ne pas se soucier des autres programmes avec lesquels il est en concurrence pour l’accès aux ressources.
1. Mémoire virtuelle et mémoire physique
La mémoire virtuelle se caractérise par le fait que les programmes ne manipulent en réalité, sans en avoir conscience, que des adresses mémoire virtuelles qui ne correspondent pas directement à des emplacements physiques en mémoire vive, mais sont traduites en adresses physiques par le processeur et le système d’exploitation.
Cette approche est particulièrement utile dans un environnement de multiprogrammation, où plusieurs programmes sont exécutés en même temps. Chaque programme peut utiliser des adresses virtuelles qui sont indépendantes des autres programmes, ce qui permet d’éviter les conflits entre eux et d’isoler leur espace mémoire respectif. Cela garantit que même si plusieurs programmes tournent simultanément, chacun pense avoir accès à une large mémoire continue et privée, alors que la mémoire physique est partagée et limitée.
Le processeur et le noyau jouent ensemble un rôle clé dans cette traduction des adresses. Lorsqu’un programme fait référence à une adresse virtuelle, le processeur utilise un mécanisme interne pour la convertir en une adresse physique dans la RAM. Cette traduction permet au système de gérer la mémoire de manière plus flexible, en assignant des blocs de mémoire physique à différents programmes selon les besoins, tout en protégeant l’intégrité de chaque programme et en optimisant...
Multiprogrammation, multitâche et multithreading
La multiprogrammation (multiprogramming) désigne la capacité d’un système d’exploitation à exécuter plusieurs programmes en mémoire simultanément, permettant ainsi une meilleure utilisation du processeur. Chaque programme occupe une portion de la mémoire et le processeur alterne rapidement entre eux, bien que seulement un programme s’exécute à un moment donné.
Le multitâche (multitasking) va plus loin en permettant à plusieurs tâches ou processus d’être exécutés simultanément, non seulement en alternant entre eux sur un même processeur (multitâche préemptif), mais aussi, dans des systèmes multiprocesseurs ou multicœurs, en les exécutant véritablement en parallèle.
Le multithreading, quant à lui, est une technique qui permet à un programme de diviser son exécution en plusieurs sous-processus appelés threads (ou « fils d’exécution », mais ce n’est pas utilisé). Chaque thread peut être exécuté indépendamment, soit en parallèle sur plusieurs cœurs, soit en alternance sur un seul processeur, ce qui permet une meilleure réactivité et un traitement plus efficace des tâches concurrentes au sein d’un même programme. Dans ce contexte, le multiprocessing identifie les situations où les processus peuvent réellement bénéficier d’exécution parallèle sur plusieurs cœurs au lieu de partager le temps sur un seul cœur (quand bien même chacun de ces cœurs est partagé en « temps partagé » à son tour.)
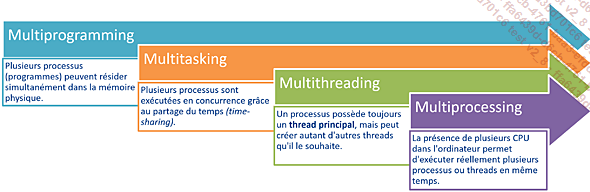
Figure 3-15 - Différentes notions
Voyons en détail toutes ces notions.
1. L’apparition de la multiprogrammation
L’apparition de la multiprogrammation remonte aux années 1950 et 1960, avec le développement des premiers systèmes d’exploitation avancés pour les grands ordinateurs centraux (mainframes). À cette époque, les ordinateurs étaient coûteux et les temps d’utilisation devaient être optimisés. Les premiers systèmes étaient monoprogrammés...
Le contrôle de la concurrence
Le contrôle de la concurrence est une mécanique essentielle qui doit impérativement être implémentée correctement par les programmes utilisant le calcul concurrent ou parallèle pour garantir la cohérence de leur fonctionnement.
1. Les problèmes de concurrence
Les problèmes de concurrence surviennent lorsque plusieurs processus ou threads tentent de s’exécuter simultanément et interagissent avec des ressources partagées, comme la mémoire ou des structures de données. Dans un système concurrent, où les tâches s’exécutent de manière désordonnée ou en se chevauchant dans le temps, divers problèmes peuvent apparaître si l’accès aux ressources partagées n’est pas correctement coordonné. Parmi ces problèmes figurent les conditions de course (race conditions), où le résultat des opérations dépend de l’ordre ou du timing des processus, et des incohérences de données, quand plusieurs threads peuvent lire ou écrire des données en même temps, en écrasant leurs résultats mutuels, entraînant des valeurs incorrectes ou corrompues
Le défi principal de la concurrence est de s’assurer que, lorsque plusieurs threads ou processus accèdent à des ressources partagées, cela se fait de manière contrôlée et prévisible. C’est là qu’intervient le contrôle de la concurrence. Il s’agit d’un ensemble de techniques et de mécanismes destinés à gérer les interactions entre les opérations concurrentes afin de garantir la cohérence des données et la stabilité du système.
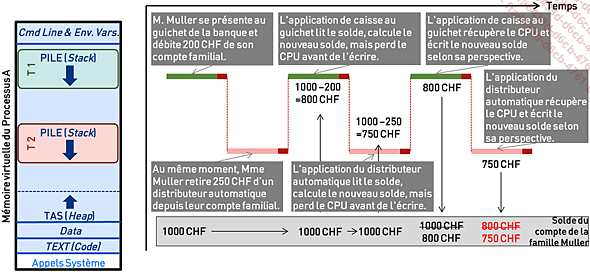
Figure 3-21 - Un problème classique de synchronisation de threads
2. L’exclusion mutuelle
L’exclusion mutuelle (MUTEX - MUTual EXclusion) est le concept fondamental utilisé pour résoudre les problèmes liés à la concurrence dans les systèmes où plusieurs processus ou threads accèdent à des ressources partagées. L’idée de l’exclusion mutuelle est de garantir qu’à tout moment, un seul thread peut accéder à...
Le support du réseau
La gestion du réseau dans un ordinateur repose sur un ensemble de mécanismes matériels et logiciels qui ensemble réalisent les techniques de communication entre différents ordinateurs et dispositifs connectés. Cela inclut la gestion des protocoles de communication comme TCP/IP, qui définissent comment les données sont envoyées et reçues à travers les réseaux, ainsi que les interfaces telles que les cartes réseau et les sockets. Le système d’exploitation joue un rôle central en orchestrant l’acheminement des données vers les adresses IP et ports.
Nous reviendrons largement sur l’histoire des réseaux informatiques dans le chapitre Des premiers réseaux aux réseaux sociaux qui leur est dédié. Mais prenons un peu de temps ici pour comprendre comment les communications réseau sont prises en charge dans un ordinateur.
1. La notion de socket
Un socket réseau est un composant logiciel qui représente un point de communication, un « tuyau » virtuel pour l’envoi et la réception de données à travers un réseau.
Elle constitue une interface entre une application et la pile de protocoles réseau, permettant ainsi une communication fluide entre différents ordinateurs ou dispositifs sur le réseau. La structure et les propriétés d’un socket sont définies par une API (Application Programming Interface), qui fait partie de l’architecture réseau et propose des primitives permettant aux applications d’interagir avec les composants du système d’exploitation qui régissent la manière dont les données transitent entre les couches de communication.
Un socket n’existe que durant la durée de vie du processus qui l’a créé. Cela signifie qu’il est initialisé et utilisé par un programme en cours d’exécution sur un ordinateur (ou nœud) pour établir une connexion et échanger des données, puis il est détruit lorsque le programme termine son exécution ou ferme explicitement la connexion.
Dans le contexte de l’Internet et des protocoles TCP/IP (Transmission Control Protocol / Internet Protocol), le terme...
Pour en savoir plus
Nous avons vu dans ce chapitre les principes de fonctionnement d’un ordinateur les plus fondamentaux : les fondations matérielles sous-jacentes à toute machine informatique moderne, la gestion complexe des processus, la mémoire virtuelle, la gestion concurrence et l’accès au réseau. Il est notamment communément considéré dans le monde de la programmation système que le triplet Socket, Thread, Sémaphore en forme la base. Ce chapitre a pour vocation de donner au lecteur les clés de compréhension de ces notions fondamentales.
Mais la « programmation système » est, bien sûr, un univers beaucoup plus riche. Il reste énormément de choses à découvrir sur les mécaniques pilotant le fonctionnement des ordinateurs, par exemple :
-
Les interruptions, ou IRQ (Interrupt Requests) sont des signaux envoyés au processeur pour indiquer qu’un événement nécessitant son attention immédiate s’est produit. Elles permettent de gérer efficacement les interactions entre le matériel et les logiciels en interrompant temporairement l’exécution d’un programme pour traiter une tâche prioritaire.
Lorsqu’une interruption est déclenchée (par exemple, par un périphérique comme un clavier ou une carte...