
L’architecture des SI : du mainframe au Big Data
Introduction
Un système d’information (SI - ou Information System - IS) est un ensemble organisé de ressources (logiciels, données, processus, etc.) permettant de collecter, stocker, traiter et diffuser l’information au sein d’une organisation pour soutenir ses activités et sa prise de décision. La notion d’« architecture des systèmes d’information » est apparue avec l’ère des mainframes dans les années 1950-1960. Ces premiers SI étaient monolithiques, avec des architectures simples et peu de composants logiciels interconnectés. Puis, avec l’évolution des technologies et la multiplication des besoins d’entreprise, leurs architectures sont devenues de plus en plus élaborées. L’essor de l’informatique distribuée a entraîné, d’une part, l’apparition d’une multitude de composants logiciels au sein d’un même applicatif (bases de données, services backend, services web, etc.) et, d’autre part, la multiplication des applicatifs au sein des SI. Cette évolution a conduit à une gestion de plus en plus complexe, nécessitant des architectures plus évolutives et flexibles.
Ce chapitre présente l’évolution de l’architecture des systèmes d’information, des mainframes à l’émergence...
Des architectures monolithiques au modèle 3-tiers
L’évolution des architectures logicielles, des systèmes monolithiques aux modèles en 3-tiers, reflète la quête d’une meilleure modularité, évolutivité et résilience dans le développement des systèmes d’information en passant d’un bloc unique à une séparation claire des responsabilités.
1. Retour sur le mainframe
L’histoire des architectures des systèmes d’information commence véritablement avec l’introduction des ordinateurs centraux, ou mainframes, dans les années 1950. À cette époque, ces machines géantes étaient au cœur de l’informatique d’entreprise. Le traitement des données était centralisé : toute la logique métier, la gestion des bases de données et les traitements étaient effectués sur un seul ordinateur, souvent dans un seul et même logiciel. Dans ce contexte, la découpe en modules logiques différenciés relevait davantage de l’art que de la méthode. Les utilisateurs accédaient au système via des terminaux passifs, qui se contentaient de capturer et d’afficher des informations sans traitement local. Cette approche rudimentaire a cependant permis aux grandes organisations (banques, compagnies d’assurance, gouvernements) d’informatiser très tôt leurs processus. Par exemple, elles pouvaient gérer les transactions financières dans les systèmes de paiement ou encore des bases de données clients.
L’architecture des systèmes fonctionnant sur mainframe était le plus souvent monolithique, c’est-à-dire que toute la logique applicative, la présentation des données et leur gestion étaient étroitement intégrées dans une seule et même entité logicielle, souvent emmêlées et sans grande structuration. Ils étaient conçus pour traiter de grandes quantités de données de manière stable et avec des performances prédictibles, ce qui était crucial pour des secteurs tels que la finance et l’administration publique, où les erreurs pouvaient avoir des conséquences graves. Dans...
Le modèle relationnel de données
Le modèle relationnel de données a été, et demeure largement, la pierre angulaire de la gestion moderne des bases de données.
1. Les origines
Le modèle relationnel de données a été formalisé par Edgar F. Codd, un informaticien britannique travaillant chez IBM, dans un article publié en 1970 intitulé « A Relational Model of Data for Large Shared Data Banks ». Codd proposait une approche radicalement nouvelle de la gestion des données, basée sur les mathématiques, et plus précisément sur la théorie des ensembles et la logique de prédicats.
Avant cela, les systèmes de gestion de bases de données (SGBD ou DBMS - DataBase Management System) utilisaient des modèles hiérarchiques ou en réseau. Ces modèles étaient rigides et dépendaient fortement de la manière dont les données étaient physiquement stockées sur les disques, essentiellement sous la forme de fichiers indexés.
2. Les premières bases de données
Les premières approches de haut niveau pour organiser des jeux de données structuraient celles-ci logiquement en arbres (modèle hiérarchique) ou en graphes complexes (modèle en réseau).
Le modèle hiérarchique, comme son nom l’indique, organisait les données en une structure en forme arborescente, avec des relations parent-enfant. Ce modèle manquait de flexibilité car il imposait une navigation rigide dans la structure pour accéder aux données. Le modèle en réseau, popularisé par le standard CODASYL, permettait de représenter des relations plus complexes entre les données en utilisant des graphes. Cependant, il était toujours nécessaire de connaître les chemins d’accès pour manipuler les données, rendant les opérations d’interrogation des données peu flexibles.
Mais l’organisation des données sous-jacente aux deux modèles reposait sur l’utilisation de fichiers indexés. Aussi, il faut relever que seuls les plus gros systèmes déployaient ces modèles de plus haut niveau (hiérarchique ou en réseau). ...
L’hégémonie du modèle relationnel sur le SI opérationnel
Le modèle relationnel et le modèle 3 tiers ont dominé les systèmes d’information opérationnels pendant vingt ans, largement soutenus par des géants comme IBM, Oracle et Microsoft. Cette stabilité a longtemps freiné l’innovation dans la gestion des données et le design des systèmes d’information, jusqu’à ce que les startups du Web apportent la génération suivante d’innovations pour répondre aux besoins de scalabilité et de flexibilité accrus auxquels elles ont été confrontées.
1. Le système d’information opérationnel
Le système d’information opérationnel désigne l’ensemble des composants logiciels, processus et outils informatiques utilisés par une organisation pour gérer ses activités courantes de manière efficace et automatisée. Il englobe les applicatifs, bases de données, serveurs et réseaux qui permettent de traiter les informations nécessaires à la gestion des transactions, des opérations internes, et des flux d’information au sein de l’entreprise. On l’appelle également souvent le système transactionnel.
Ces systèmes sont essentiels pour assurer la continuité des processus quotidiens dans des domaines variés comme la gestion des stocks, le suivi des commandes, les transactions financières, la gestion du référentiel client ou encore la gestion des ressources humaines. Ils sont conçus pour garantir une disponibilité et une fiabilité très élevées, et nécessitent impérativement la cohérence transactionnelle.
Le système d’information opérationnel exprime en effet des exigences strictes en matière de performance, d’intégrité des données et de sécurité, car les erreurs ou interruptions peuvent avoir un impact direct sur les opérations commerciales de l’entreprise...
L’apparition du SI analytique
Le système d’information analytique, ou système d’information décisionnel, souvent aussi désigné par BI - Business Intelligence, s’est développé au fil des décennies pour répondre aux besoins croissants des entreprises en matière de prise de décision basée sur les données. Alors que les systèmes d’information opérationnels se concentraient principalement sur la gestion des opérations quotidiennes, les systèmes d’information décisionnels ont été conçus pour permettre aux entreprises de collecter, stocker et analyser des données sur des périodes plus longues et dans le but de faciliter la prise de décisions stratégiques.
1. Les origines de la BI et des systèmes décisionnels
L’idée de systèmes d’information spécifiques pour la décision stratégique remonte aux années 1960, avec les premiers concepts de systèmes d’aide à la décision (DSS - Decision Support Systems). Ces systèmes avaient pour objectif d’aider les dirigeants d’entreprise à analyser des données et à simuler des scénarios pour faciliter la prise de décision. À cette époque, ces systèmes étaient relativement rudimentaires, reposant sur des modèles statistiques ou des outils de calcul spécifiques à chaque entreprise.
À la fin des années 1970, avec l’explosion des bases de données relationnelles (SGBDR) et des premières grandes entreprises informatiques comme IBM, les grandes entreprises ont commencé à utiliser des systèmes spécifiques pour collecter et analyser des données à plus grande échelle. Cependant, les systèmes d’information étaient encore largement orientés vers des données opérationnelles, stockées dans des bases de données transactionnelles, et n’étaient pas toujours adaptés à l’analyse des données en masse pour le support décisionnel.
2. Apparition des Data Warehouses et des Data Marts
À la fin des années 1980, une révolution s’opère...
Du mainframe aux applications web
L’apparition des technologies web dans les années 1990 a été une étape majeure dans l’histoire de l’informatique. Cette période a vu un changement progressif mais radical, où les applications dites à « clients lourds » (applications bureautiques) ont cédé leur place aux « clients légers » (applications web), une évolution qui a complètement changé la technologie du tiers de présentation dans le modèle 3-tiers. Cette transformation a permis de significativement simplifier le développement des applicatifs clients, mais surtout de fusionner les technologies internet et intranet.
D’une certaine façon, c’est l’architecture applicative et technique du modèle 3 tiers qui a évolué au travers des âges, Cette évolution est représentée sur la figure 7-7. Attention, on parle bien ici d’architecture applicative et technique au sein du modèle 3 tiers et non pas d’une évolution de l’architecture du SI, qui quant à lui, demeure toujours et encore notre fidèle modèle 3-tiers sur son SGBDR.

Figure 7-7 - L’évolution du modèle 3-tiers
Voyons ces différentes étapes en détail.
1. À l’époque des mainframes
À l’époque des mainframes, le modèle 3-tiers, bien qu’encore informel dans sa définition, pouvait être perçu à travers l’organisation fonctionnelle des systèmes d’information.
Le tiers des données était centralisé sur le mainframe lui-même, initialement sous la forme de bases de données hiérarchiques comme IMS ou de fichiers structurés accédés via VSAM, gérés par des programmes en COBOL. Ces bases de données sont rapidement remplacées par des bases de données plus modernes qui permettent d’implémenter la logique orientée données directement au sein de la base de données (hors COBOL donc) au moyen de procédures stockées.
La logique applicative était codée souvent en COBOL ou en FORTRAN sur le même mainframe, regroupant à la fois les traitements...
Nos systèmes d’information ont vingt ans
Comme nous l’avons vu jusqu’ici, les technologies à la base des applicatifs d’entreprise (ou grand public par ailleurs) ont formidablement évolué. Cependant, au début des années 2000, un constat peut être fait : en vingt ans, les systèmes d’information des entreprises ont été conçus selon des paradigmes architecturaux quasiment inchangés, une approche invariable, sans réelles innovations ou changements de paradigme.
D’un côté, les Systèmes d’Information opérationnels (SIO) soutiennent les opérations quotidiennes et les activités commerciales. Dans ces systèmes, l’architecture en 3-tiers et le modèle de base de données relationnelle ont dominé pendant trente ans. De l’autre côté, les systèmes d’aide à la décision (ou Business Intelligence - BI ou systèmes d’information analytiques), où le modèle architectural de l’entrepôt de données (Data Warehouse) a régné pendant presque vingt ans.
1. Une architecture héritée sans réelle transformation
Malgré l’évolution des technologies au cours des décennies, l’architecture sous-jacente des systèmes d’information est restée fondamentalement inchangée. Dans les années 1980, COBOL sur les systèmes hôtes d’IBM était prédominant, tandis que des technologies comme Java, pour le tiers métier, et HTML/JavaScript pour le tiers client, ont rapidement émergé comme standard dans les années 2000.
Cependant, à nouveau, si les technologies applicatives et les langages...
Les géants du Web
Ainsi, les années 2000 à 2010 ont été marquées par une période de transformations majeures dans le paysage des technologies de l’information. Les capacités matérielles ont connu des améliorations significatives, et le commerce électronique ainsi que les échanges sur Internet ont littéralement explosé. Ce bouleversement a poussé certaines entreprises, qualifiées de géants du Web (Yahoo!, Facebook, Google, Amazon, eBay, Twitter...), à rechercher de nouvelles architectures puisque les modèles et bases de données traditionnels atteignaient leurs limites dans ces cas d’usage extrêmes.
Particulièrement, les bases de données relationnelles sont, par conception, difficiles à faire évoluer à grande échelle et se sont avérées peu appropriées à ces nouveaux modèles d’affaires.
1. Les problèmes des géants du Web
Les géants du Web ont donc dû trouver de nouvelles solutions techniques pour relever des défis critiques pour leur activité :
-
Google : comment indexer l’ensemble du Web et garantir un temps de réponse inférieur à une seconde pour chaque requête - tout en maintenant un service gratuit pour l’utilisateur ?
-
Facebook : comment connecter des milliards d’utilisateurs, afficher leurs fils d’actualités en quasi temps réel, et analyser leur comportement pour optimiser la publicité ?
-
Amazon : comment construire un moteur de recommandations de produits pour des dizaines de millions de clients sur des millions de références ?
-
eBay : comment permettre une recherche dans les enchères, même avec des fautes d’orthographe ?
Ces exemples sont volontairement simplifiés, car les enjeux auxquels font face les géants du Web vont bien au-delà de ces simples questions.
Derrière ces problématiques commerciales se cachent des défis techniques colossaux tels que :
-
Comment interroger une base de données contenant des milliers de milliards de documents en temps réel ?
-
Comment lire des millions de fichiers de plusieurs mégaoctets rapidement ?
En fin de compte, tout cela se résume...
Le Big Data et la distribution des données
Nous ne faisons pas seulement face à une augmentation exponentielle de la quantité de données générées ; nous disposons également, aujourd’hui, des technologies nécessaires pour analyser, exploiter et extraire des informations précieuses à partir de ces données. C’est là toute la révolution du Big Data : non seulement les volumes de données ont explosé, mais surtout, il est désormais possible de les transformer en insights stratégiques pour les entreprises.
Les géants du Web ont inventé une nouvelle famille de technologies, appelées technologies Big Data, qui leur ont permis de dépasser les limites des architectures traditionnelles et de faire face au déluge de données auquel ils ont été rapidement confrontés. Ils ont ouvert une voie qui bénéficie aujourd’hui aussi largement aux entreprises traditionnelles.
1. Les fondements du Big Data
Pour contourner les limites des architectures traditionnelles, les géants du Web ont inventé de nouveaux paradigmes architecturaux et ont redéfini la manière de concevoir les systèmes d’information en s’appuyant sur trois idées fondamentales.
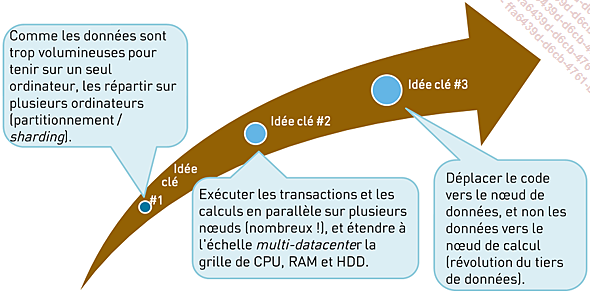
Figure 7-13 - Les fondements du Big Data
Idée clé 1 : la distribution des données
Face à l’impossibilité de stocker l’intégralité des données sur une seule machine, la solution consiste à diviser ces données et à les distribuer sur un nombre de machines suffisant pour les gérer. Cette répartition des données, parfois appelée sharding ou partitionnement, implique non seulement de diviser les ensembles de données en fragments ou partitions, mais aussi de toujours répliquer ces fragments. La réplication est cruciale pour assurer la redondance et la disponibilité des données et nous aborderons plus en détail ces mécanismes ultérieurement.
Idée clé 2 : la scalabilité horizontale
Similairement aux données réparties sur plusieurs machines, il est possible de distribuer la charge de calcul sur autant de nœuds que nécessaire pour supporter le volume...
Le théorème CAP
Comme mentionné ci-dessus, la distribution des données (sharding et réplication) a d’importantes conséquences qui doivent impérativement être prises en compte lors de la conception des systèmes qui l’exploitent. Une d’entre elles en particulier est fondamentale et exprimée par le théorème CAP présenté dans cette section.
1. Propriétés des systèmes distribués
Dans les systèmes de gestion de bases de données relationnels (SGBDR), on attend des transactions qu’elles respectent un ensemble de propriétés fondamentales, regroupées sous l’acronyme ACID : Atomicité, Cohérence, Isolation et Durabilité. Ces propriétés garantissent que les opérations effectuées sur une base de données relationnelle sont fiables et cohérentes à tout moment.
Dans les systèmes distribués (comme les bases de données NoSQL dont nous parlerons plus loin), la gestion des transactions est envisagée différemment. On se concentre alors sur des propriétés qui prennent en compte les spécificités des environnements distribués. Voyons trois propriétés clés.
a. Disponibilité
La disponibilité (availability) est une propriété des clusters de bases de données. Un cluster est considéré comme disponible si à toute requête envoyée, un client reçoit systématiquement et immédiatement la réponse ou alors a minima un accusé de réception de la part du système. Cela signifie que la requête est garantie d’être prise en compte par le système, même si son traitement n’est peut-être pas immédiat et qu’elle peut être mise en attente. En d’autres termes, un système disponible doit, au minimum, accuser réception de chaque requête sans délai.
Dans la pratique, la disponibilité est souvent exprimée en pourcentage. Par exemple, une disponibilité de 99,99 % signifie que le système est indisponible au maximum 0,01 % du temps, ce qui équivaut à environ 53 minutes d’indisponibilité...
La notion de quorum
Dans les architectures distribuées, la notion de quorum - un mot emprunté au latin qui signifie « le nombre minimal nécessaire » - désigne le nombre minimal de nœuds d’un système qui doivent se mettre d’accord ou simplement participer pour qu’une opération, quelle qu’elle soit, puisse être considérée comme valide ou qu’une décision puisse être prise. Cette idée est fondamentale pour garantir la cohérence, la disponibilité et la tolérance aux pannes dans des systèmes où les composants (nœuds) communiquent via un réseau.
1. La nécessité d’un quorum
Les systèmes distribués doivent résoudre des problèmes liés à la nature asynchrone et potentiellement défaillante des nœuds :
-
Tolérance aux pannes : si certains nœuds sont inaccessibles ou en panne, un quorum permet au système de continuer à fonctionner sans attendre que tous les nœuds soient disponibles.
-
Consensus : dans des protocoles comme Paxos ou Raft - des protocoles standardisés utilisés par de nombreux systèmes distribués - ou au sein de protocoles propriétaires, le quorum garantit qu’une décision prise par une majorité des nœuds est visible par d’autres, même en cas de pannes ou de partitions réseau.
-
Cohérence : en présence de plusieurs copies de données (réplication), le quorum assure que les opérations de lecture et d’écriture respectent les contraintes de cohérence.
Imaginons un système distribué sans quorum, où une opération est validée dès qu’un seul nœud confirme son exécution. Si ce nœud subit une panne immédiatement après avoir validé l’opération, les autres nœuds ne sauront jamais que l’opération a eu lieu. Il en résulterait des incohérences majeures, comme des mises à jour perdues (lost update) ou des décisions contradictoires.
Pire encore, si plusieurs nœuds tentent indépendamment d’exécuter la même opération sans...
L’ère NoSQL
Les bases de données NoSQL représentent une nouvelle génération de systèmes de gestion de données, née principalement des technologies développées par les géants du Web. Ces bases se distinguent par leur capacité à scalabiliser horizontalement de manière native, en répartissant les données sur un grand nombre de serveurs, et par leur abandon des comportements et fonctionnalités traditionnels des SGBDR (systèmes de gestion de bases de données relationnelles).
Contrairement aux bases relationnelles, qui reposent sur des principes bien établis comme les transactions ACID et la normalisation stricte, les bases NoSQL adoptent une approche plus flexible, conçue pour répondre aux défis posés par la gestion de volumes massifs de données dans des environnements distribués.
En renonçant à certaines garanties de cohérence (immédiate/stricte) et en offrant une scalabilité horizontale infinie, les bases NoSQL se concentrent sur la performance, la disponibilité et la tolérance aux pannes, des aspects essentiels pour les applications modernes à grande échelle, telles que les réseaux sociaux, le commerce en ligne, et les services de streaming.
Ces systèmes ont ainsi redéfini les paradigmes de gestion des données, en sacrifiant certaines propriétés des SGBDR pour privilégier la performance et l’adaptabilité aux architectures distribuées.
1. Les bases de données NoSQL
Une base de données NoSQL - initialement désignant not-SQL pour « non relationnelle » - propose un mécanisme de stockage et d’interrogation des données qui repose sur des modèles différents des relations tabulaires utilisées dans les bases de données relationnelles et le langage SQL. Le terme NoSQL a été popularisé dans les années 2000 avec l’émergence de ces solutions disruptives en réponse aux besoins spécifiques des entreprises du Web 2.0.
Les bases de données NoSQL sont de plus en plus utilisées dans les environnements de Big Data et des applications web en temps réel, où la gestion de vastes volumes de données...
Hadoop
Hadoop est un framework open source conçu pour le traitement et le stockage de données massives (Big Data) de manière distribuée. S’appuyant sur le modèle MapReduce et sur son système de fichiers distribué (HDFS), il permet de gérer efficacement des volumes de données à l’échelle de plusieurs pétaoctets, en exploitant des clusters de machines standards (commodity hardware) pour offrir une haute tolérance aux pannes et une scalabilité horizontale inégalée.
1. Les publications de Google
Aux alentours de 2005, Google a publié deux articles fondamentaux qui allaient révolutionner la gestion des données à grande échelle. Le premier, intitulé « GFS - The Google File System », exposait la conception et la mise en œuvre chez Google d’un système de fichiers distribué capable de gérer d’immenses volumes de données sur des clusters de serveurs.
Le second article, « MapReduce », présentait un paradigme de programmation distribué adopté par Google et permettant de traiter efficacement les données stockées sur ce système de fichiers distribué. Nous verrons en détail MapReduce plus loin dans cette section.
Quelques années plus tard, Google a publié un autre article, intitulé « BigTable », qui expliquait la conception et la mise en place d’une base de données orientée colonnes reposant sur les principes de GFS et MapReduce. Cette base de données distribuée offrait une scalabilité massive tout en garantissant des performances élevées pour des applications telles que l’indexation du Web, le traitement de grandes quantités de données ou l’analyse en temps réel.
C’est en découvrant ces publications que Doug Cutting, alors responsable du projet Apache Lucene, décida de créer une implémentation open source de ces concepts. Cette initiative a donné naissance à ce qui deviendrait l’un des piliers du Big Data moderne : Hadoop. Ce projet a permis de démocratiser l’accès à des infrastructures de traitement de données massivement distribuées...
Une alternative au grid computing
Le grid computing, que nous avons présenté au chapitre Des usages militaires à l’ère digitale, à la section L’informatisation massive des entreprises, a été une étape essentielle dans l’évolution des architectures distribuées, offrant une première solution aux besoins de calcul massif pour des applications scientifiques et industrielles.
Cependant, avec l’apparition du Big Data, les limitations du grid computing - en termes de scalabilité, de traitement de données en temps réel et de flexibilité - mais surtout son coût extrêmement élevé sont devenues évidents. Les technologies Big Data ont ainsi remplacé les grilles de calcul en fournissant des architectures plus distribuées, plus accessibles et adaptées à la nature changeante des besoins en données des grandes entreprises modernes et des géants du Web.
1. Fonctionnement et différences avec les technologies Big Data
Le grid computing repose sur un modèle de calcul distribué, mais avec une approche centralisée et en batch. Voyons quelques différences fondamentales avec les technologies Big Data modernes :
-
Modèle de traitement : le grid computing fonctionne par soumission de tâches complexes en batch, organisées en files d’attente....
Les Data Lake et paradigmes associés
Un Data Lake est une nouvelle architecture de dépôt de données dans lequel les informations sont stockées dans leur format naturel ou brut, sans avoir été transformées ou traitées au préalable. Cette architecture s’oppose radicalement à l’approche Data Warehouse qui préconise de transformer et polir soigneusement la donnée avant de la stocker dans le système analytique.
Il représente généralement un réservoir unique regroupant des copies brutes des systèmes sources, aussi bien les données métiers du système d’information opérationnel que les traces d’audit et les logs techniques, mais également potentiellement des données de capteurs, des données issues des réseaux sociaux, etc., ainsi que des données transformées utilisées pour des tâches telles que le reporting, la visualisation, l’analyse avancée ou l’apprentissage machine.
Un Data Lake peut contenir différents types de données :
-
données structurées provenant de bases relationnelles ;
-
données semi-structurées (fichiers CSV, logs, XML, JSON) ;
-
données non structurées (emails, documents, PDF) ;
-
données binaires (images, audio, vidéo).
1. Le principe du Data Lake
L’adoption massive d’Hadoop au sein d’un nombre croissant d’applications analytiques à grande échelle intégrant de plus en plus facilement des sources de données massives et variées, a démocratisé le concept de Data Lake d’entreprise, évoqué initialement en 2010 par James Dixon, CTO de Pentaho. Si le besoin de sortir de la structuration extrêmement contraignante des architectures des entrepôts de données (Data Warehouse) n’était pas nouveau, il fallut attendre l’apparition d’Hadoop pour que cela devienne enfin possible.
Un Data Lake se distingue des architectures habituelles au sein des systèmes décisionnels par trois principes clés :
-
Collecter tout : un Data Lake vise à contenir toutes les données possibles, qu’il s’agisse de sources brutes collectées...
Les architectures streaming
Hadoop a été conçu initialement pour révolutionner les systèmes analytiques en permettant de stocker des données massives et effectuer des opérations de lecture/écriture (IO - Input / Output) de façon massivement parallèle en bénéficiant des disques durs de nombreuses machines. Mais avec l’évolution des technologies NoSQL et l’augmentation de la mémoire disponible, de plus en plus de systèmes et technologies (sur et hors Hadoop) se sont mis à travailler en mémoire. Cette évolution à son tour a permis l’émergence de nouvelles techniques pour travailler en streaming (flux) et en temps réel aussi bien au sein du système opérationnel que pour les besoins analytiques.
Les données en flux (streaming data) désignent des données générées de manière continue, généralement en grands volumes et à haute vitesse. Une source de données en flux concerne généralement des événements à traiter au fur et à mesure de leur occurrence, tels qu’un utilisateur cliquant sur un lien dans une page web, un capteur transmettant en temps réel une information comme la température actuelle, ou encore des transactions boursières.
Une architecture streaming (traitement en flux) est une approche intégrant divers composants logiciels conçus pour ingérer et traiter de grandes quantités de données provenant de plusieurs sources en temps réel. Contrairement aux approches orientées données plus traditionnelles, qui se concentrent sur l’écriture et la lecture par lots, une architecture de traitement en flux consomme les données dès leur génération, les stocke de manière persistante, mais les traite aussi immédiatement en flux tendu au travers de toute la chaîne de composants applicatifs nécessaires pour les usages considérés, comme des outils d’analyse, d’agrégation, de publication, etc.
Un système en temps réel dans ce contexte est un système événementiel, conçu pour être disponible, scalable et stable, capable de prendre des décisions (ou d’effectuer...
L’ère du cloud
Des débuts des bases de données NoSQL à la fin des années 2000 à aujourd’hui, l’univers technologique informatique a continué à beaucoup évoluer. L’ère du cloud a marqué une rupture dans la manière dont les entreprises conçoivent, déploient et exploitent leurs infrastructures informatiques.
Le cloud désigne un modèle d’informatique à la demande où des ressources (comme le stockage, la puissance de calcul ou les applications) sont accessibles à distance via Internet, sans que l’utilisateur ait à gérer l’infrastructure sous-jacente.
Grâce à des plateformes flexibles et évolutives, le cloud permet de répondre aux besoins croissants des organisations en matière de scalabilité, de performance et de résilience. Les technologies cloud-native, conçues spécifiquement pour tirer parti des environnements distribués et décentralisés du cloud, offrent des avantages comme le déploiement rapide, la résilience intégrée et souvent une meilleure gestion des coûts grâce à la facturation à l’usage.
Ces technologies, basées sur des concepts comme les microservices, les conteneurs (Docker, Kubernetes) et le serverless, ne se limitent toutefois pas aux environnements de cloud public. Elles trouvent également leur utilité dans des infrastructures on-premise (à l’interne) ou hybrides, permettant aux entreprises de bénéficier de l’agilité et de la flexibilité des technologies et modèles du cloud tout en conservant un contrôle plus strict sur leurs données et leur infrastructure. Ainsi, les technologies cloud-native apportent une réponse efficace aux défis...
Kubernetes
Kubernetes est une plateforme open source, tirant son inspiration et même sa base technologique de Google Borg, l’un des premiers systèmes de gestion de clusters de Google. Il a été publié en tant que composant open source par Google en 2014, avec une première version officielle en 2015.
1. Introduction à Kubernetes
Kubernetes offre les fonctionnalités suivantes :
-
Déploiement automatisé des applications logicielles ainsi que la mise à l’échelle, la tolérance aux pannes et la gestion à travers un cluster de nœuds.
-
Gestion des composants d’exécution des applications sous forme de conteneurs, avec des unités applicatives regroupées sous forme de PODs.
-
Plusieurs services essentiels, tels que la localisation des services, un réseau virtuel, la gestion des volumes distribués et bien d’autres (en somme, tout ce dont on a besoin pour déployer des applications sur un cluster de calculs distribués).
Aujourd’hui, Kubernetes émerge comme un standard dans le rôle du système d’exploitation du cloud. Il est disponible sous plusieurs distributions dont les principales sont :
-
PKS (Pivotal Container Service) ;
-
Red Hat OpenShift ;
-
Canonical Kubernetes ;
-
Google Kubernetes Engine (GKE) / Amazon EKS / Azure Kubernetes Service (AKS).
Kubernetes suit une architecture distribuée qui permet de déployer et gérer des applications à grande échelle sur des infrastructures cloud ou on-premise. Grâce à ses fonctionnalités avancées, telles que le réseau virtuel et la localisation des services, Kubernetes est devenu un pilier essentiel pour les environnements cloud-native, facilitant l’automatisation, la résilience et la portabilité des applications à travers différents environnements.
Sa flexibilité et sa capacité à s’adapter à la complexité des besoins métier modernes en font un incontournable de l’informatique aussi bien cloud qu’interne (on-premise).
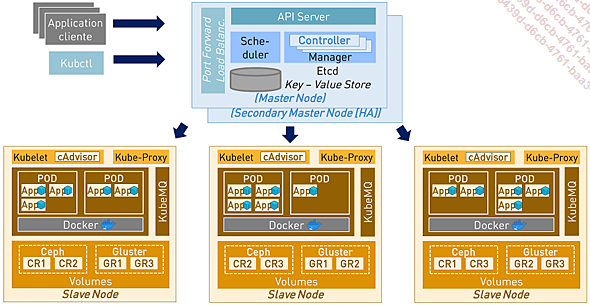
Figure 7-31 - L’architecture de Kubernetes
Aujourd’hui, Kubernetes s’est imposé comme la principale plateforme d’orchestration pour gérer toute application conteneurisée. Sa capacité à automatiser...
Les microservices
L’architecture microservices, variante du style architectural orienté services (SOA - Service Oriented Architecture), organise une application sous forme de services faiblement couplés. Le lecteur curieux saura faire un saut au prochain chapitre La programmation, à la section La conception orientée objet qui parle plus en détail des architectures SOA.
Dans une architecture microservices, les services sont fins et les protocoles de communication sont légers. Voyons quelques-unes de ses caractéristiques principales :
-
Les services dans une architecture microservices (MSA) sont de petite taille, basés sur la messagerie (communication asynchrone), délimités par des contextes, développés de manière autonome, déployables indépendamment, décentralisés et conçus avec des processus automatisés de construction et de mise en production.
-
Ces services communiquent en utilisant des protocoles réseau ou techniques de communication agnostiques aux technologies des services eux-mêmes, comme JMS, Kafka ou HTTP.
-
Ils sont organisés autour des capacités métier, chaque service étant responsable d’une fonction spécifique au sein de l’entreprise.
-
Ils peuvent être implémentés en utilisant des langages de programmation, des bases de données, et des environnements matériels et logiciels différents, selon ce qui est le mieux adapté aux besoins. Ceci n’est cependant en aucun cas une exigence stricte. Par exemple, Spring Cloud est souvent utilisé pour réaliser une architecture MSA et dans ce cas il s’agit d’une approche homogène (tout en Java).
1. Les architecture microservices
Dès 2005, Peter Rodgers a introduit le terme « Micro-Web-Services » lors d’une présentation à la conférence Web Services Edge. Toutefois, le nom du style architectural a véritablement été adopté en 2012, au moment où les microservices ont commencé à se répandre. Kubernetes a joué un rôle crucial dans la démocratisation de cette approche architecturale mais aujourd’hui un autre grand acteur se distingue également dans...
L’évolution des systèmes d’information
Aujourd’hui, l’évolution rapide des technologies disponibles au sein des systèmes d’information, marquée par l’émergence du cloud, des microservices et des technologies de scalabilité, redessine les frontières entre les systèmes opérationnels et analytiques. Aussi, dans cet univers en profonde transformation, le modèle relationnel, malgré ses limites, continue de prouver sa robustesse et sa pertinence pour de nombreux cas d’usage, témoignant de sa pérennité face aux nouvelles architectures.
1. La convergence des mondes
Nous avons parcouru un long chemin dans cet article. Nous sommes partis des premières architectures sur mainframe, avons exploré les besoins de scalabilité horizontale des géants du Web, les raisons derrière ces besoins et les défis associés, pour finalement aborder les microservices et la scalabilité des composants individuels des systèmes d’information.
Les besoins initiaux des géants du Web étaient principalement liés à la gestion massive de données et à la nécessité de scalabiliser le traitement de manière linéaire avec la distribution du stockage. Aujourd’hui, l’informatique en cloud et les services SaaS (Software as a Service) sur le cloud répondent à des besoins quelque peu différents.
Les premières technologies liées au Big Data étaient principalement (mais pas exclusivement) orientées vers des cas d’usage en analyse de données et ciblées pour les systèmes d’information analytiques (SIA). Cependant, avec l’émergence de technologies comme NoSQL, NewSQL, et plus récemment Kubernetes et les microservices, l’accent s’est déplacé vers...