
Segmentation
But du chapitre et prérequis
Dans le chapitre précédent, nous avons décrit comment les réseaux de neurones convolutionnels peuvent être adaptés pour réaliser une autre tâche que la classification : la détection.
Dans ce chapitre, nous allons décrire comment ces réseaux peuvent être adaptés pour réaliser la segmentation. Après avoir décrit les différents types de segmentation, ainsi que les métriques et les fonctions-coût utilisées pour ces réseaux, nous décrirons les meilleurs modèles disponibles.
Nous verrons que la segmentation peut être considérée comme une combinaison de classification et de détection. Ainsi, les métriques, les fonctions-coût, et les architectures utilisées seront proches de ce que nous avons déjà vu au cours de cet ouvrage.
Pour conclure ce chapitre, nous implémenterons notre propre modèle de segmentation sémantique avec Keras et TensorFlow.
Avant de lire ce chapitre, il est préférable d’avoir lu le chapitre Réseaux de neurones à convolution, ainsi que le chapitre précédent sur la détection.
Segmentation sémantique, d’instances et panoptique
1. Différents types de segmentation
Le principe de la segmentation est d’identifier à quelle classe appartient chaque pixel d’une image.
Il existe plusieurs types de segmentation.
La segmentation sémantique est historiquement le premier type de segmentation pour lequel des réseaux ont été développés. Cette tâche consiste à assigner une classe à chaque pixel ; il s’agit donc d’une extension directe de la classification.

Segmentation sémantique
Le réseau le plus approprié pour ce type de segmentation est le réseau U-Net, proposé en 2015, et ses dérivés, que nous décrirons dans la section Segmentation sémantique par U-Net de ce chapitre.
Les réseaux de segmentation sémantique sont généralement très performants, et ils conviennent pour de nombreux types d’applications. Ils présentent toutefois une limitation : les différents objets appartenant à une même classe ne sont pas séparés.
La segmentation d’instances a été conçue pour pallier cet inconvénient. Ce type de segmentation allie la détection à la segmentation, et vise à segmenter les différentes instances de différentes classes. Ainsi, les différents objets appartenant à une même classe peuvent être séparés.

Segmentation d’instances
Les réseaux les plus performants pour ce type de segmentation sont les réseaux Mask R-CNN et YOLACT, proposés respectivement en 2017 et 2019. Ces réseaux, inspirés des réseaux de détection R-CNN et YOLO, seront décrits dans la section Segmentation d’instances de ce chapitre.
Les réseaux...
Métriques de la segmentation
Les métriques utilisées pour évaluer un algorithme de la segmentation sont très proches de celles utilisées pour la classification et la détection.
Elles sont cependant calculées légèrement différemment selon que la tâche concerne la segmentation sémantique ou la segmentation d’instances.
1. Justesse
En classification, la justesse (on parle d’accuracy en anglais) représente la proportion d’images correctement classifiées sur le nombre total d’images.
En segmentation, la justesse représente la proportion de pixels correctement classifiés sur le nombre total de pixels. Nous pouvons donc calculer une valeur de justesse pour chaque image.
Comme en classification, cette métrique est très facile à calculer, elle peut cependant ne pas être représentative de la performance réelle du modèle si les différents objets ont des tailles très différentes.
Ainsi, en segmentation sémantique, si le fond comprend beaucoup plus de pixels que l’objet, la segmentation de l’objet n’aura que peu d’influence sur la valeur de la justesse.
D’une manière générale, la valeur de la justesse dépend de la taille relative des différentes classes.

Valeurs de la justesse dans le cas où la plupart des pixels appartiennent à une des classes. Les erreurs des pixels appartenant à la classe minoritaire n’ont que peu d’influence sur la valeur de la justesse.
En pratique, il est plus courant d’utiliser l’indice de Jaccard ou le coefficient de Dice pour évaluer la précision de la segmentation.
2. Indice de Jaccard
La plupart des métriques utilisées pour mesurer la performance d’un modèle de détection peuvent également être utilisées pour mesurer la performance d’un modèle de segmentation.
En effet, la seule différence entre les deux applications est la forme des objets : tandis que la détection ne définit que des rectangles, la segmentation peut définir des formes quelconques.
Il est donc possible d’adapter le calcul de l’indice de Jaccard (aussi appelé IoU, pour Intersection over Union, c’est-à-dire...
Fonctions-coût
Comme celles utilisées pour optimiser les réseaux de détection, les fonctions-coût utilisées dans les réseaux de segmentation sont généralement composées de plusieurs termes, qui peuvent être combinés selon les besoins.
1. Erreur de classification
Les réseaux de segmentation sémantique et panoptique utilisent des fonctions représentant l’erreur de classification en chaque pixel.
Parmi ces fonctions, on retrouve les mêmes que celles utilisées pour entraîner les réseaux de classification, notamment l’entropie croisée, binaire ou catégorielle. Ces fonctions sont calculées en chaque pixel, et leurs valeurs sont moyennées pour donner une unique valeur pour l’ensemble de l’image.
a. Entropie croisée
Rappelons la formule de l’entropie croisée, que nous avions introduite dans le chapitre Classifieurs linéaires.
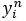 l’étiquette réelle d’un pixel
l’étiquette réelle d’un pixel 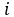 de l’image segmentée
de l’image segmentée 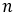 , et
, et 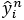 sa prédiction.
Ces deux éléments sont des vecteurs représentant
la probabilité de chacune des classes possibles au format
dit "un parmi n" et se présentent de la manière
suivante :
sa prédiction.
Ces deux éléments sont des vecteurs représentant
la probabilité de chacune des classes possibles au format
dit "un parmi n" et se présentent de la manière
suivante :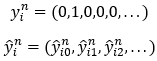 , tous les éléments sont nuls,
sauf celui correspondant à la classe réelle...
, tous les éléments sont nuls,
sauf celui correspondant à la classe réelle...Segmentation sémantique par U-Net
Pour la segmentation sémantique, c’est l’architecture U-Net qui est la plus répandue. Elle a été proposée en 2015 pour la segmentation de cellules dans des images biomédicales, mais elle s’est avérée être très efficace pour une grande variété d’applications.
Nous commençons par décrire son architecture générale, et les raisons pour lesquelles cette architecture a été choisie, avant d’entrer dans les détails.
1. Architecture
a. Contraction et expansion
L’architecture générale du réseau U-Net est extrêmement simple. C’est un réseau entièrement convolutif en forme de « U » (d’où son nom).
Il se compose de deux parties : la contraction et l’expansion.
La contraction se compose de couches de convolution et de couches de sous-échantillonnage par agrégation. Dans cette partie, au fur et à mesure des couches, les dimensions spatiales sont réduites, tandis que la profondeur s’accroît.
Cette partie permet aux couches de convolution de voir des portions de l’image de plus en plus grandes, et donc d’utiliser le contexte de l’image. Cette partie a également l’avantage d’être peu coûteuse en mémoire et en temps de calcul, puisque les convolutions s’appliquent à des images de taille très réduite.
À l’issue de cette partie, nous disposons d’une carte de caractéristiques dont les dimensions spatiales sont très réduites, mais dont la profondeur est très grande.
Cette image passe ensuite par la partie d’expansion. Cette partie se compose de couches de convolution et de couches de suréchantillonnage (nous verrons plus loin la manière dont ce suréchantillonnage est réalisé en pratique). De manière symétrique à la contraction, les dimensions spatiales de l’image augmentent au fur et à mesure des couches, tandis que la profondeur se réduit.
Cette partie permet d’augmenter la résolution spatiale de la segmentation.
Finalement, en sortie de la dernière couche, l’image finale a pratiquement la même...
Segmentation d’instances
La segmentation d’instances est proche de la détection, c’est pour ce réseau que les principaux réseaux sont des extensions de réseaux de détection. Dans cette partie, nous allons décrire Mask R-CNN, basé sur Faster R-CNN, et YOLACT, basé sur YOLO.
1. Mask R-CNN
a. Rappel de l’architecture de Faster R-CNN
Nous avons décrit dans le chapitre précédent l’architecture du réseau Faster R-CNN.
Nous la rappelons brièvement ici.
Le réseau Faster R-CNN est composé de plusieurs blocs appliqués successivement.
Le premier bloc, appelé réseau de base, est un réseau de neurones à convolution, appliqué à l’image originale pour en déduire une image de caractéristiques.
Le second bloc contient un réseau de proposition de régions, un réseau convolutionnel appliqué à l’image de caractéristiques obtenue en sortie du bloc précédent. Ce second bloc donne en sortie une grande quantité de régions, chacune avec une probabilité de contenir un objet d’intérêt, quelle que soit sa classe. Il fournit également, pour chaque région, un ajustement de sa position pour coller au plus près à l’objet.
C’est le troisième bloc qui effectue la classification : chacune des régions passe par un nouveau réseau convolutionnel, qui estime la probabilité d’appartenance de la région à chacune des classes d’intérêt.
Enfin, un algorithme de suppression des régions non maximales permet de ne conserver que les régions les plus prometteuses.
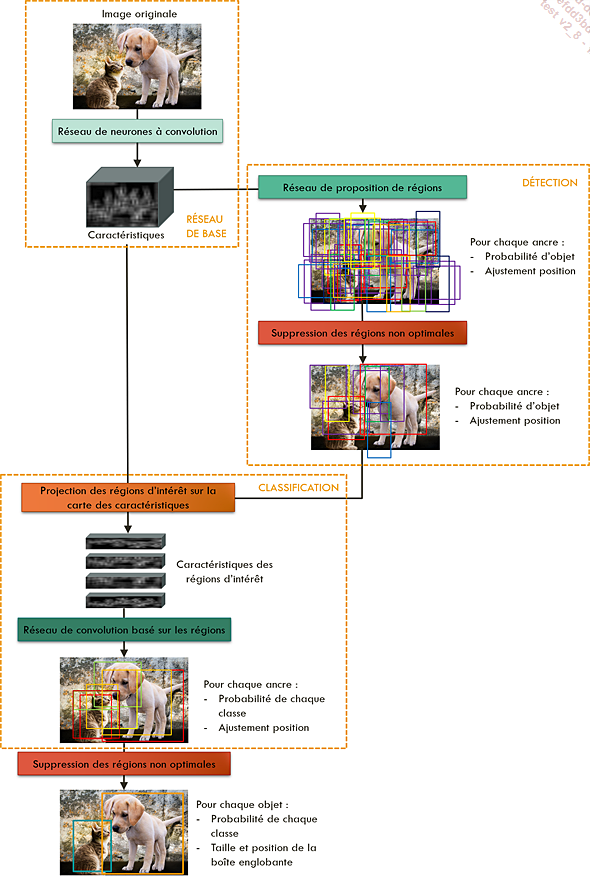
Architecture générale du réseau Faster R-CNN
b. Architecture de Mask R-CNN
L’architecture de Mask R-CNN est identique à celle de Faster R-CNN, à ceci près qu’un bloc supplémentaire est ajouté. La sortie du bloc de proposition de régions, au lieu de n’alimenter que le bloc de classification, alimente maintenant un autre bloc en parallèle. Ce bloc additionnel est un bloc de segmentation, et il a pour but de définir un masque recouvrant l’objet dans chaque région proposée, et pour chacune des classes d’intérêt....
Segmentation panoptique
1. Principe global
Le concept de segmentation panoptique a été introduit en 2019 afin d’unifier les concepts de segmentation sémantique et d’instances.
C’est un concept récent, et pour l’instant il existe relativement peu de réseaux qui permettent de réaliser une telle segmentation.
D’une manière générale, ces réseaux réalisent une segmentation sémantique et une segmentation d’instances sur une même image d’entrée, puis fusionnent les sorties des deux segmentations.
Les premiers réseaux proposés réalisent en parallèle les deux segmentations, puis fusionnent leurs sorties de la manière suivante :
-
Pour les classes correspondant à des objets, ce sont les prédictions de la segmentation d’instances qui sont utilisées.
-
Pour les classes correspondant à de la matière, ce sont les prédictions de la segmentation sémantique qui sont utilisées.
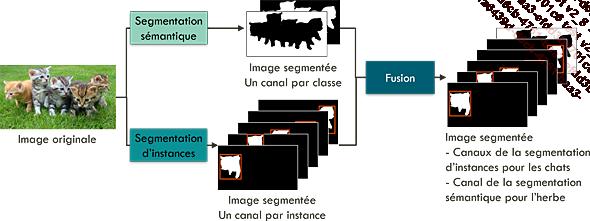
Segmentation panoptique réalisant en parallèle les segmentations sémantique et d’instances, puis fusionnant leurs sorties selon les types de chaque classe
Cette approche a deux inconvénients majeurs. Tout d’abord, elle est très inefficace en temps de calculs, car elle applique deux réseaux entiers de segmentation. Ensuite, elle ignore...
Choisir et trouver un modèle de segmentation
Comme pour la détection, de nombreux réseaux de segmentation sont régulièrement publiés, chacun promettant d’être plus rapide et plus précis que tous les précédents.
Comment choisir un réseau de segmentation ?
Le choix d’un réseau particulier se fait selon les mêmes trois critères que le choix d’un réseau de détection : sa précision, son temps de calcul, et sa facilité d’utilisation.
Parce qu’ils sont plus complexes à entraîner que les réseaux de détection, les réseaux de segmentation font l’objet de moins d’articles de vulgarisation. Pour en sélectionner un, les deux sources principales d’informations que vous pouvez utiliser sont les suivantes :
-
La publication scientifique qui accompagne généralement la publication d’un nouveau réseau, souvent disponible sur le site d’archives ouvert arXiv (https://arxiv.org/).
-
Le site Papers with code (https://paperswithcode.com), qui regroupe les descriptions et les liens vers les implémentations de plusieurs réseaux.
Gardez à l’esprit que, comme pour la classification et la détection, la performance d’un réseau ne dépend pas uniquement de son architecture, mais également des données...
Exercice pratique : implémentation, entraînement et application de U-Net
Nous allons maintenant mettre en pratique les fondements théoriques développés au cours de ce chapitre en recodant le modèle U-Net. Nous l’entraînerons ensuite sur des données de chats et de chiens, et l’appliquerons à la segmentation de ces deux classes.
Le code de cette partie se trouve dans le notebook "Segmentation.ipynb".
Conclusion
Dans ce chapitre, nous avons défini les différents types de tâches de segmentation. Nous avons montré comment l’architecture des réseaux convolutionnels pouvait être adaptée pour réaliser la segmentation, et nous avons décrit le fonctionnement des réseaux les plus performants pour chacun de ces différents types.
Dans le prochain chapitre, nous décrirons d’une manière plus générale la manière dont les réseaux convolutionnels peuvent être adaptés pour réaliser une large gamme de tâches en traitement d’images, et pas seulement la classification, la détection et la segmentation.



