
Organiser ses données
Introduction
Dans ce chapitre, nous allons aborder un sujet essentiel pour concevoir et mettre en œuvre une solution analytique avec Microsoft Fabric : la différence entre le Data Warehouse (Entrepôt de données) et le Data Lakehouse (Lac de données), qui sont deux services que nous trouvons dans Fabric pour stocker, organiser et requêter des données. Ces deux services peuvent être source de confusion, car ils répondent à des besoins et des usages très similaires même s’ils ont leurs particularités propres ainsi que leurs avantages et leurs inconvénients respectifs.
L’objectif de ce chapitre est de vous aider à comprendre les spécificités mais aussi la complémentarité de l’un et de l’autre de ces services Fabric, et de vous donner tous les critères qui vont vous aider à faire le choix entre l’un et l’autre, ou alors d’utiliser les deux et de les faire travailler ensemble pour atteindre l’objectif de votre solution analytique.
Un peu d’histoire : OLTP, OLAP et Big Data
1. Deux univers inconciliables : OLTP et OLAP
Avant d’entrer dans le vif du sujet, il nous semble important de faire un peu d’histoire sur les solutions data. En effet, pour comprendre la différence entre le Data Warehouse et le Data Lakehouse aujourd’hui, il faut remonter quelques années en arrière et étudier l’évolution au fil du temps des systèmes de stockage et de traitement des données, en fonction des besoins, des technologies et des paradigmes qui ont émergé.
Depuis toujours, on a deux familles de solutions de données, ou en tout cas de moteurs de stockage ou de façon d’utiliser la donnée, qui s’opposent : le OLTP d’un côté et le OLAP de l’autre. Le premier est l’acronyme de Online Transactional Processing, l’autre est l’acronyme de Online Analytical Processing. Le premier est pour ce qu’on appelle les données opérationnelles, celles qui vont être branchées sur une application de gestion par exemple, et qui vont donc être optimisées dans leur stockage et dans leur requêtage pour ces mêmes applications. Le second est pour ce qu’on appelle l’analytique, ou plus communément les Data Warehouse. Ici, les données vont être stockées avec une certaine modélisation et donc un mode de stockage et un mode de requêtage optimisés pour l’analyse de données.
Si on devait illustrer la spécificité des Data Warehouses, nous pourrions dire qu’ils sont faits pour requêter des gros volumes...
Le Data Warehouse : un entrepôt de données structurées et optimisées pour l’analytique
Un Data Warehouse, ou entrepôt de données en français, est un concept qui a été inventé dans les années 90, et qui est devenu un produit qu’on trouve sur le marché pour stocker des données à des fins analytiques. L’idée du Data Warehouse, c’est de se dire qu’on a un entrepôt, qui sert à stocker des données, et qui dit entrepôt, dit que les choses sont rangées, empilées, organisées, pour pouvoir retrouver l’information facilement et rapidement. Au départ un pattern de modélisation, le Data Warehouse est devenu finalement, grâce aux bases de données relationnelles, un vrai produit qu’on peut utiliser pour stocker de la donnée.
Le Data Warehouse s’accompagne depuis toujours des principes et avantages suivants :
-
La maturité des bases de données et du SQL : le Data Warehouse est une base de données relationnelle, qui utilise le langage SQL pour créer, manipuler et requêter les données. On a donc tout l’héritage des bases de données relationnelles, qui existent depuis les années 70, et qui offrent une richesse fonctionnelle et une robustesse éprouvée.
-
Optimisé...
Le Data Lakehouse : un Data Lake structuré et optimisé pour l’analytique
Un Data Lakehouse est un concept qui a émergé à la fin des années 2010 et qui se caractérise par l’ajout d’une surcouche qui vient compléter le format Parquet en apportant un caractère transactionnel et donc en supprimant certaines des limitations intrinsèques d’un lac de données qui ne contiendrait que de la donnée inerte.
Le format Parquet, orienté colonne, rend complexe la modification de données qui est quasiment exclusivement par lignes. Pour garder la consistance des fichiers de données, chaque transaction (requête de modification) doit attendre que la précédente ait mis à jour la totalité des données concernées.
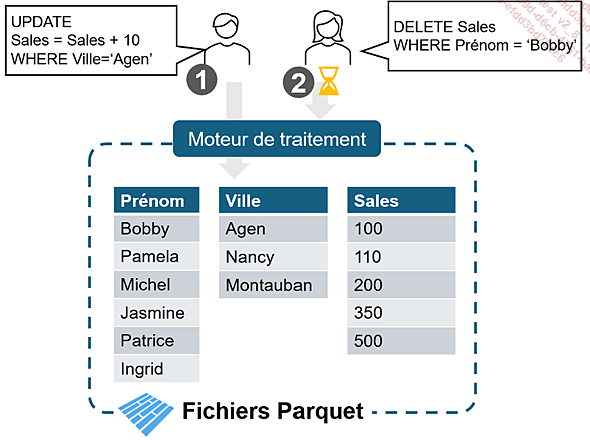
Dans les bases de données traditionnelles, un journal de transaction combiné avec un mécanisme de verrouillage plus ou moins granulaire permet de traiter plus de requêtes en parallèle.

Il existe différentes initiatives, toutes en open source, pour apporter la notion de transaction dans les Data Lakes : Delta Table, Iceberg, Hudi. Fabric travaille nativement avec le format Delta. À l’heure où nous écrivons, Microsoft a annoncé que Fabric s’ouvrait à d’autres formats utilisés dans des architectures...
Le Data Warehouse : les avantages de la maturité ?
Aujourd’hui, si l’on doit stocker des données en grande quantité dans des tables, les faire vivre en garantissant une cohérence transactionnelle quand on ajoute, modifie ou retire des données, le Lakehouse ou le Warehouse sont deux solutions équivalentes et qui s’utilisent de la même façon quand on arrive à l’étape d’analyse.
Mais alors, quelles sont les différences entre les deux et comment déterminer la meilleure option pour votre utilisation ?
Comme évoqué plus haut, le Data Warehouse bénéficie de la maturité des bases de données SQL des dernières décennies. Le premier bénéfice est un langage strict de définition et de manipulation des données en SQL.
1. Instructions DDL
Les instructions DDL, pour Data Definition Language, sont des instructions SQL qui permettent manipuler les objets du Datawarehouse. Elles permettent entre autres de définir précisément le schéma et les contraintes sur les tables ou encore de créer des vues, des fonctions et des procédures stockées.
Il est ainsi possible de créer une table avec un schéma très strict au-delà du simple typage via le langage SQL. On peut ajouter des contraintes de clé primaire ou de clés étrangères ou indiquer que des colonnes peuvent accepter ou pas des valeurs nulles.
Attention, il y a quand même des limitations par rapport à une base de données SQL Server. Certaines instructions T-SQL ou fonctionnalités ne sont pas disponibles. Nous pouvons citer par exemple l’instruction CREATE INDEX, qui permet d’ajouter des index pour optimiser la lecture.
L’autre limitation qui peut réduire l’avantage de l’intégrité référentielle d’un Warehouse dans Fabric est le fait que les contraintes sur les colonnes, incluant...
Différences et convergences
1. Faire du SQL sur un Lakehouse
Microsoft cherche à rapprocher l’usage du langage T-SQL, quel que soit le stockage utilisé derrière. Ainsi, un Lakehouse expose un point de terminaison SQL qui permet de s’y interfacer comme à un entrepôt de données et d’envoyer des instructions SQL.
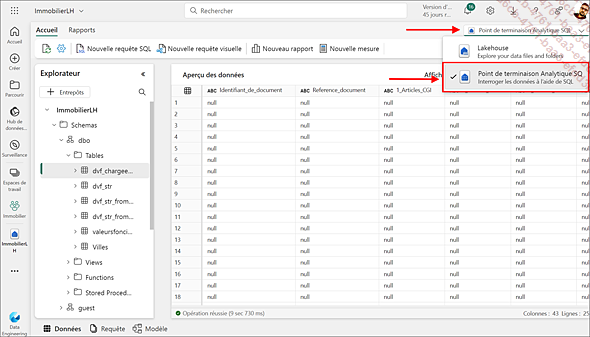
Toutefois, même si les instructions de type SELECT sont totalement supportées, ce point de terminaison n’offre pas de possibilité de modifier des données avec des instructions INSERT, UPDATE ou DELETE. Et le support des instructions DDL est très limité.
Le langage Spark permet aussi de travailler en SQL avec le Spark SQL mais rappelons que ce langage n’est qu’un sous-ensemble du standard SQL (normes ISO ou ANSI). Le module Spark SQL permet de traduire une instruction SQL dans le langage natif de Spark écrit à l’origine en langage SCALA. Il sera également soumis à des limitations mais différentes de celles du point de terminaison.
Pour requêter des données dans un Lakehouse avec le langage Spark SQL, il faut passer par un Notebook. Soit on change le langage par défaut du bloc-notes en indiquant Spark SQL, soit on change le langage d’une cellule de code en particulier avec l’instruction %%sql.
%%sql
SELECT zip_code, label, COUNT(*) FROM VentesLH.Villes
WHERE department_number = 52
GROUP BY zip_code, label
LIMIT 100 
En conclusion, même si le langage SQL est présent partout dans Microsoft Fabric, le choix du moteur de stockage, Lakehouse ou Warehouse, est très important et les limitations doivent être prises en compte très tôt dans la conception de votre solution. On peut rêver d’un futur où tous les langages, SQL ou Spark, fonctionneraient de la même façon sur tous les stockages, vous préservant d’avoir à faire un choix entre l’un et l’autre. Mais il y a encore une longue route pour imaginer une uniformisation complète, Microsoft s’efforce de gommer les frictions pour simplifier la vie des développeurs et utilisateurs.
2. L’impact du stockage physique
Il existe des différences entre le stockage dans un Lakehouse et dans un Warehouse. Dans un Warehouse, vous n’avez pas accès directement...
Comment choisir ?
Maintenant que nous avons présenté les différences essentielles entre le Lakehouse et le Warehouse, il est temps de vous aider à faire un choix. Autant avouer tout de suite que le choix est difficile étant donné la quasi-parité entre les deux. Le choix doit se faire sur des détails ou sur des critères non techniques, comme votre existant, vos compétences ou votre appétence pour l’un ou l’autre.
1. Points forts de chacun des services
Nous allons comparer leurs points forts respectifs et exclusifs dans le tableau ci-dessous en nous concentrant sur les aspects qui font la différence et qui peuvent être déterminants pour votre choix.
|
Lakehouse |
Warehouse |
|
Raccourcis Les raccourcis n’existent que dans le service Lakehouse. Leur utilisation est essentielle pour ségréger et gouverner la donnée entre différents espaces de travail. |
Langage T-SQL plus complet Le Warehouse est nativement compatible avec le SQL et la surface du langage supportée est très large, beaucoup plus que dans le Lakehouse. |
|
Données non tabulaires Seul le Lakehouse permet de stocker et manipuler des données semi-structurées ou non structurées comme du texte, du JSON ou du XML dans sa zone Fichiers. |
Sécurité granulaire Le Warehouse offre la meilleure proposition pour sécuriser vos données de façon granulaire (tables, lignes, colonnes, masquage). |
|
Ouverture Le lakehouse avec ses fichiers Delta ou Iceberg permet d’utiliser différents moteurs de manipulation de données, qu’ils soient internes (Spark, SQL, pandas) ou externes (Databricks, Snowflake, etc.). |
Transactions Si votre manipulation de données implique des transactions plus ou moins... |
Exemple d’une chaîne complète Lakehouse et Warehouse
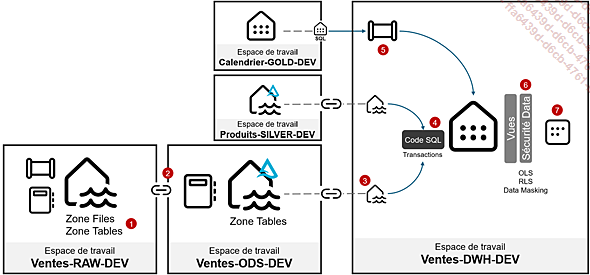
Afin d’illustrer les différences du Data Warehouse et du Lakehouse, nous proposons d’imaginer la conception d’une chaîne complète utilisant l’un et l’autre et bénéficiant de leurs avantages respectifs.
Prenons par exemple un scénario d’analyse des ventes où nous devons exposer un schéma en étoile des ventes et des produits dans le temps.
-
1. Quand on manipule des fichiers (CSV, Excel, JSON, etc.), l’usage d’un Lakehouse est indispensable car l’accès aux fichiers non managés (ie. non tables) se fait exclusivement via un Lakehouse. Cela reste vrai même en utilisant un lien vers un stockage externe (Azure Data Lake Storage, Amazon S3, Google Cloud Storage, etc.). Gérer des fichiers et des répertoires avec Spark dans un Notebook est plus pratique pour remplir des tables Delta simples avec des données encore à l’état brut.
-
2. Nous utilisons un second espace de travail pour séparer la préparation des données à une autre équipe. Les tables du premier Lakehouse sont accessibles via un raccourci qui n’est disponible que dans un Lakehouse. L’équipe de développement qui prépare les données travaille en Spark avec des Notebooks.
-
3. Les tables préparées...
Bases de données en miroir
Dans la plateforme Fabric, un élément est très comparable au Data Warehouse : il s’agit des bases de données en miroir. Celles-ci partagent les attributs d’un data warehouse et en remplissent les mêmes fonctions. Mais les bases de données en miroir sont dédiées à un cas d’usage bien particulier.
Techniquement, c’est un Data Warehouse. En interne, ce sont des tables au format Delta, utilisant l’optimisation V-Order gérée par Fabric. La base de données en miroir propose la création de vues, de procédures stockées ou de fonction comme dans le Data Warehouse mais ne permet pas de créer son propre schéma ni ses propres tables.
1. Quel est l’usage des bases de données en miroir ?
Une base de données en miroir est une copie locale d’une source de données relationnelle externe synchronisée en quasi-temps réel.

Les sources supportées à date sont Azure SQL, Azure CosmosDB et Snowflake (flocon de neige en français). Microsoft a annoncé d’autres sources à venir comme PostgreSQL ou encore SQL Server On-Premises (référence : https://go.fabricbook.fr/ch7-13).
Attention : de nombreuses limitations comme le nom ou le type des colonnes ou encore certaines fonctionnalités sur la table vous empêcheront de mettre en miroir une table. Par exemple, la base Azure SQL doit avoir un tiers de service minimum de 100 DTU (S3) ou bien être en Serverless. La page suivante de la documentation présente l’ensemble des limitations actuelles : https://go.fabricbook.fr/ch7-14
Concrètement, dans quel cas utiliser une base de données en miroir ? Très basiquement, dès que vous avez une source...
Synthèse
Dans ce chapitre, nous avons présenté les concepts et les services liés au data warehousing et au Data Lakehouse dans Microsoft Fabric. Nous avons vu que ces deux solutions ont de très nombreux points communs et sont complémentaires.
Toutefois, il existe encore des cas où l’entrepôt de données présente des avantages, notamment lorsque les données sont structurées, que les schémas sont stables et que les requêtes SQL sont privilégiées pour manipuler de la donnée en lecture et écriture, en particulier avec des transactions.
Le Lakehouse, quant à lui, est incontournable quand il s’agit de manipuler des fichiers et des données non structurées ou semi-structurées. Il est aussi obligatoire pour bénéficier des raccourcis vers des données de OneLake provenant d’autres espaces de travail ou encore de service de stockage externe. Son approche moderne de la gestion des données avec un langage de développement comme Spark, s’appuyant sur des concepts issus du monde du développement et bénéficiant de frameworks plus riches que le SQL permet des opportunités innovantes. Citons par exemple la possibilité de mixer de la manipulation de données traditionnelle avec l’utilisation d’API, ou d’insérer du...