Consommer des flux Open Data
Trouver des flux
1. Data.gouv.fr
En France, la destination numéro un pour trouver de la donnée publique est le portail Open Data de l’État, fourni par ETALAB. ETALAB fait partie du Secrétariat Général à la Modernisation de l’Action Publique, et est donc directement rattaché au cabinet du Premier ministre, ce qui souligne l’importance de sa mission. Le site data.gouv.fr non seulement propose de la donnée, mais également agrège et centralise des données de nombreux autres fournisseurs au niveau national, comme l’INSEE, l’IGN, etc.
La page d’accueil du site propose un système de recherche par mot-clé ou par catégorie, puis affiche une sélection des jeux de données souvent ou dernièrement utilisés, ainsi que des mises en forme particulières. Le site supporte en effet le dépôt par tout un chacun d’une carte, d’un graphique ou d’un site apportant de la richesse à un jeu de données publié.
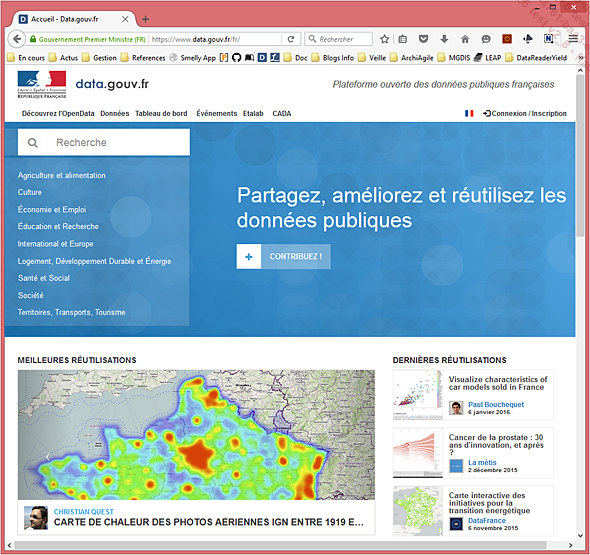
Lors d’une recherche, les résultats sont fournis sous forme de vignettes avec quelques métadonnées de base. Une bande de recherche sur la droite fournit des facettes qui permettent de filtrer les résultats plus avant. Ces facettes permettent de restreindre la donnée par la granularité territoriale, les formats de fichiers...
Principes de consommation
1. Les questions à se poser
La question de la recherche de données a été traitée ci-dessus assez rapidement car les exemples dans les trois chapitres qui suivent vont donner de nombreuses pistes complémentaires. De la même manière, les façons de consommer ces données, de les nettoyer ou les analyser, vont être traitées en profondeur par la suite, donc cette section a seulement pour objectif de donner les grands principes de consommation de la donnée.
Le lien étant fort entre Open Data et open source, l’auteur a cherché dans cet ouvrage à équilibrer au maximum les usages d’outils propriétaires avec ceux d’outils libres, ou à défaut disposant d’une version communautaire gratuite. Tous les outils sont accessibles financièrement, y compris à des particuliers, et donc également à des PME ou des administrations consommatrices de taille réduite.
Outre les outils, quelques questions sont à se poser avant de consommer la donnée. Elles peuvent paraître des évidences une fois énoncées, mais il n’empêche qu’elles constituent une première étape de sélection permettant de transformer une demande fonctionnelle (le souhait du consommateur d’obtenir de l’information) en un ensemble d’exigences...
Filtrage de données avec Power Query
Un des premiers besoins qui se présente lorsqu’un fichier de données est récupéré sur un site de données publiques est de filtrer la masse de données parfois inutiles pour le besoin courant. Le cas d’école est lorsque seules des données de portée locale vous sont utiles, alors que la source contient les données pour la totalité du pays. Un autre exemple est lorsque les données sont fournies pour les dix dernières années, alors que seules les plus récentes ont du sens pour retrouver l’information qui vous préoccupe.
L’idéal dans ces cas est que le producteur de la donnée vous fournisse un moyen de filtrer en amont la donnée, au moyen d’une API. Si ce n’est pas le cas, il sera nécessaire de filtrer la donnée en utilisant un outil.
Power Query est une des meilleures alternatives pour ce genre de manipulation. Il s’agit d’un module additionnel d’Excel dédié à la préparation des données avant analyse dans Excel. Il permet de se connecter à de nombreuses sources de données et de les nettoyer, de supprimer les doublons, de restructurer le contenu et de rajouter des informations statistiques, entre autres fonctionnalités. Power Query possède en outre les avantages de la gratuité ainsi que d’une excellente intégration à Excel, qui reste l’outil de base pour de nombreux analystes.
1. Installation de Power Query
Comme il s’agit du premier usage que nous faisons de Power Query, la présente section détaille le téléchargement et l’installation du module. Si le module est déjà installé, vous pouvez passer à la section suivante sans risque de manquer une information importante pour la suite.
a. Téléchargement
Power Query est disponible sur les versions 2010, 2013 et 2016. Depuis la version 2013, il est installé par défaut dans une version fixe, mais il est recommandé de télécharger et d’installer la toute dernière version. Pour cela, le plus simple est de se rendre sur le site http://microsoft.com et d’utiliser la fonctionnalité de recherche comme ci-dessous :
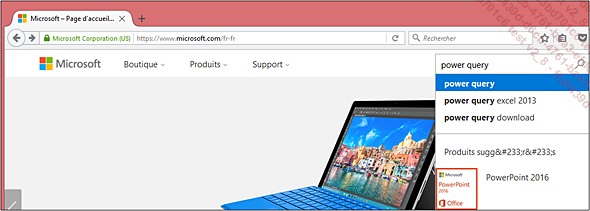
Cette recherche aboutit à...
Affinage des données avec OpenRefine
La section ci-dessous va démontrer l’usage d’un second outil de nettoyage de données, à l’approche sensiblement différente de celle utilisée par Power Query (et qui s’apparentait assez fort à un ETL).
Un ETL (Extract Transform Load) est un outil spécialisé, comme son nom l’indique, dans l’extraction, la transformation et le chargement de données. Il s’agit en général d’outils assez lourds, réservés à des traitements de masse. Ils sont donc considérés comme ne relevant pas du domaine étudié par le présent ouvrage, même si - dans des processus plus industriels de publication de données - ils ont bien sûr toute leur place.
L’idée maître d’OpenRefine est de gérer des données "sales", à savoir contenant des doublons, des données identiques a priori mais écrites de manière légèrement différentes, ce qui empêche leur équivalent informatique, etc. Google est à l’origine de ce produit initialement appelé Google Refine. Après quelques années, le produit a été transféré en un projet open source, comme l’indique le site original (https://code.google.com/p/google-refine/). Toutefois, la présence du logo Google en évidence sur l’interface utilisateur de l’outil montre que les ponts sont loin d’être coupés.
OpenRefine est disponible sur la forge open source GitHub, à l’adresse https://github.com/OpenRefine. Cette organisation contient plusieurs dépôts de projets (repository dans le vocable GitHub), dont un se nomme lui-même OpenRefine. C’est le projet principal, contenant l’application web permettant de piloter le nettoyage de jeux de données.
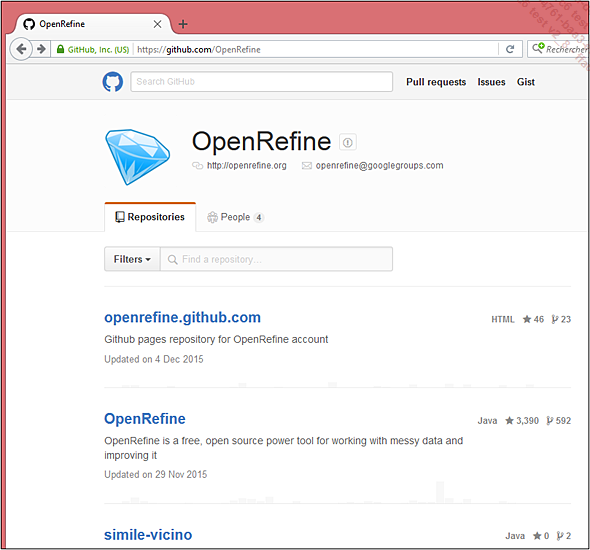
Il est possible d’accéder directement à ce projet par l’URL https://github.com/OpenRefine/OpenRefine.
1. Installation d’OpenRefine
Les téléchargements pour les différentes versions de l’outil sont disponibles dans la section releases du dépôt GitHub. Au moment de l’écriture du présent ouvrage, la release était la 2.5...
Manipulation de données structurées avec Wrangler
Open Refine est certainement un des meilleurs outils pour nettoyer de la donnée peu structurée, avec des formats étranges, des provenances multiples provoquant la présence des doublons, bref de la donnée de mauvaise qualité, bien que présentée sous forme tabulaire. Mais les sources sont parfois plus structurées dans leur contenu, tout en étant fournies sous des formes moins strictes qu’un tableau. Nous allons montrer comment utiliser dans ce cas un autre outil plus adapté.
1. Utilisation de l’ancêtre Data Wrangler
Le produit Wrangler commercialisé par Trifacta est issu d’un outil web édité par l’Université de Stanford, initialement présenté sous forme d’une application web gratuite, et nommée Data Wrangler. Bien que cette dernière ne soit plus supportée, nous allons rapidement montrer son fonctionnement sur un exemple simple, pour expliquer les caractéristiques essentielles de Wrangler, et en particulier les fonctionnalités de proposition automatique de transformation.
a. Récupération de données brutes
Pour cet exemple, nous allons simplement copier de la donnée sous forme de texte telle qu’on la trouve sur d’innombrables sites web. Par exemple :
Allez à l’adresse http://www.univ-rennes2.fr/dgs/rennes-2-chiffres.
Faites défiler la page jusqu’à trouver la liste de répartition des étudiants.
Sélectionnez le texte comme ci-dessous :

Copiez la donnée dans le presse-papiers, grâce à la commande Copier du menu contextuel ou par le raccourci-clavier [Ctrl] C.
Si cette donnée n’est plus disponible ou si vous n’avez pas la possibilité d’y accéder pour une quelconque raison, le texte brut est sauvegardé dans le fichier Texte brut pour Data Wrangler.txt, disponible en téléchargement depuis la page Informations générales, de telle manière que vous soyez en mesure de réaliser l’exercice dans les meilleures conditions.
b. Lancement de Data Wrangler
La donnée étant dans le presse-papiers, nous pouvons passer à l’étape suivante....
Recomposition de données déstructurées avec Power Query
1. Le bon outil n’est pas toujours celui qu’on croit
Le scénario suivant de préparation de données consiste à recomposer une donnée fournie selon une structure ne respectant pas les règles de l’affichage tabulaire. Il n’est en effet pas rare qu’une donnée soit relativement propre pour ce qui est des valeurs, mais qu’elle soit fournie sous une forme correspondant à une mise en page plus lisible, mais au final plus complexe à analyser, car différente d’un simple tableau.
Nous avons vu dans la section précédente que Wrangler est un bon outil pour réaliser ce genre de manipulation. Par contre, il est assez révélateur que le tout premier exercice de prise en main fourni par Data Wrangler (http://vis.stanford.edu/wrangler/app/) est en pratique plus difficile à réaliser avec Trifacta Wrangler qu’avec son prédécesseur. Du coup, nous allons reproduire l’exercice avec Power Query, car il n’est pas évident que Wrangler soit l’outil optimal pour tous les utilisateurs. La manipulation avec Power Query, illustrée ci-dessous, permettra au lecteur de choisir l’outil qui, au final, lui paraît le plus adapté à ses préférences.
2. Récupération du jeu de données déstructuré
Sur l’adresse fournie juste au-dessus, nous allons recopier le texte correspondant au jeu de données exemple par défaut, à savoir celui lié à la criminalité dans les états aux USA, comme nous l’avions fait précédemment.
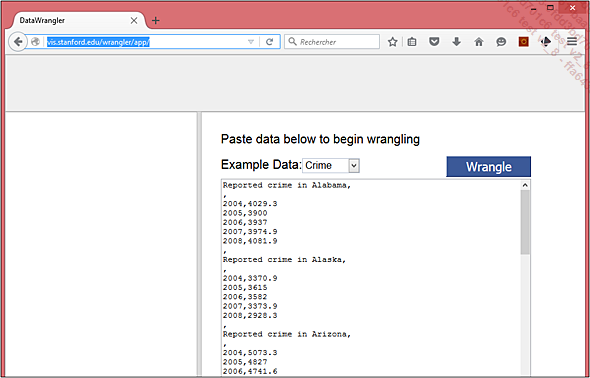
Il est clair dès le premier coup d’œil que la donnée n’est pas du tout présentée sous forme de tableau : les données sont fournies par blocs comprenant une ligne de titre embarquant l’état concerné, puis une ligne vide, puis les lignes de données pour les années connues, et enfin une ligne vide pour marquer la fin du bloc. Les virgules sont utilisées pour séparer les lignes, mais également pour séparer la valeur de l’année correspondante. Bref, une restructuration forte va être nécessaire avant de pouvoir...
Les limites de la restructuration de données
Dans les précédentes sections, nous avons montré comment utiliser Wrangler et Power Query pour retravailler des ensembles de données faiblement structurées de façon à pouvoir exploiter ces dernières par la suite. Bien sûr, il existe des cas dans lesquels même les meilleurs outils trouvent leurs limites, à savoir lorsque la déstructuration des données ne suit pas une logique particulière.
Par exemple, le fichier des effectifs de la Police municipale par commune fourni sur https://www.data.gouv.fr/fr/datasets/police-municipale-effectifs-par-commune/ sous le nom de téléchargement PM_enquete_2014_communes_ ASVP.xlsx ne suit pas une logique suffisante pour qu’il soit possible de le traiter de manière informatique. Un simple coup d’œil au fichier Excel montre que la réutilisation des données n’était clairement pas dans les objectifs du producteur.
Sur la première capture ci-dessous, le titre occupe quinze lignes en haut du fichier, ce qui posera problème à certains outils. Même dans le cas où il est possible de gérer un nombre de lignes à passer, les garanties sont faibles que le fichier de l’année suivante reste exactement sur ce nombre.
La colonne département contient comme prévu...
Autres fonctionnalités des outils
1. Power Query
Le but de la présente section n’est pas de remplacer un ouvrage sur Power Query mais au-delà de l’exemple simple de prise en main, il paraît intéressant de réaliser un tour rapide des fonctionnalités de cet outil, de façon que les utilisateurs potentiels puissent savoir si l’outil leur est adapté.
a. Retour sur un classeur
Pour démontrer les possibilités additionnelles, nous revenons sur le classeur créé un peu plus haut dans ce chapitre et qui réalise une mise au propre des données de criminalités des états américains.
Le seul fait de sélectionner une cellule du tableau créé aboutit normalement à l’affichage du volet contenant les requêtes Power Query, mais si ce n’est pas le cas, la commande correspondante se trouve dans l’onglet POWER QUERY, dans le groupe Requêtes du classeur :
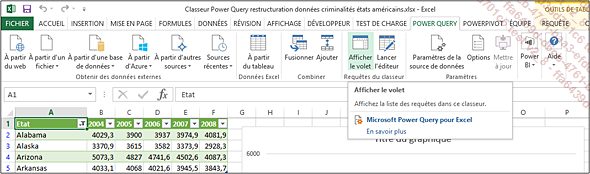
Un survol des entrées de la liste permet de retrouver les principales informations de la requête, mais aussi d’y accéder :
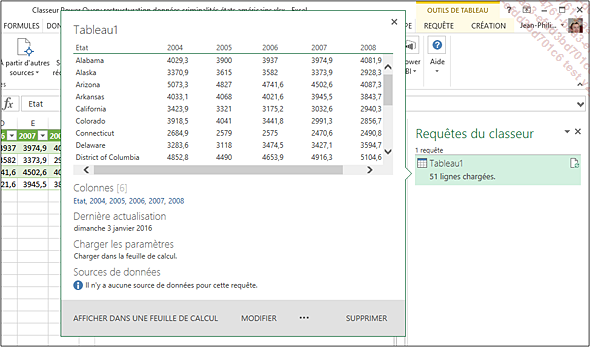
L’accès à la requête peut également être réalisé depuis le menu contextuel dans le panneau latéral :
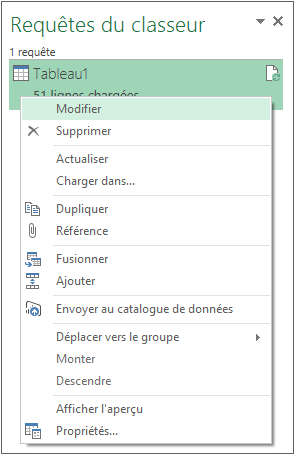
b. Autres transformations
L’onglet Transformer montre plusieurs opérations que nous n’avons pas détaillées, mais qui peuvent se révéler très utiles dans d’autres cas d’usage que les analyses très générales que nous avons opérées jusqu’ici :

Il est ainsi possible de :
-
Remplacer automatiquement certaines valeurs par d’autres, typiquement des valeurs vides par des zéros dans des colonnes numériques, ou bien des chaînes comme "inconnu" ou "N/A" par des valeurs vides.
-
Remplacer les erreurs : lors de certaines manipulations sur Power Query, certaines lignes peuvent poser problème (division par zéro, récupération de caractères dans une chaîne vide, etc.). Cette opération permet de remplacer les erreurs générées par des valeurs par défaut, ce qui permet de poursuivre sans que les erreurs ne se propagent aux opérations suivantes.
Plus loin dans l’onglet, de nombreuses autres opérations sont...