
Rappel des notions techniques de base
Virtualisation
La virtualisation est vue aujourd’hui comme le fait de pouvoir émuler les ressources matérielles. L’hyperviseur sert de couche d’abstraction qui permet l’isolation de chaque machine virtuelle de telle sorte qu’un utilisateur connecté à une de ces machines virtuelles n’aura pas conscience qu’il n’est pas sur un vrai système physique.
Pourtant, la notion de virtualisation va bien au-delà de cette vision actuelle. Cette dernière, se concentrant sur l’aspect isolation, en oublie le premier concept qui est le partage des ressources. Historiquement, l’origine de la virtualisation pouvait aisément se confondre avec le début même de l’informatique, après le temps des gros systèmes mono-utilisateurs, fonctionnant par batch. C’est IBM qui introduit, vers la fin des années soixante, le concept de CP/CMS. Ce système de virtualisation très avancé, et dont les concepts ont été repris par les autres systèmes plus récents, demeure à ce jour utilisé dans les séries « z » du matériel IBM.
Le composant CP, pour Control Program, met à disposition de l’utilisateur une émulation d’un S/360 dédié. Pour ne pas se retrouver dans des réplications de plusieurs systèmes S/360, le CMS, pour Consol Monitor System, s’occupe du partage des ressources et de leur déduplication. En faisant tourner un CMS dans chaque CP, la surcharge sur le système physique est largement diminuée. CP/CMS a permis l’exécution d’applications qui ne sont pas écrites spécialement pour faire du time sharing.
Des systèmes multitâches et multi-utilisateurs sont ensuite apparus et ont conquis le marché des serveurs...
Conteneurisation
1. À l’origine : cgroups et namespace
Le concept de conteneurisation, même s’il n’est pas explicitement nommé, est présent dès les débuts de l’informatique. Dès que le partage des ressources devenait une problématique, l’isolation de l’utilisation de celles-ci devenait une priorité. De par sa nature même, le cœur du système informatique est séquentiel : un processeur n’exécute qu’une instruction à la fois. Malgré l’introduction du multithreading, ou des architectures multiprocesseurs, cet état de fait demeure et rend contre-intuitif l’exécution isolée et parallélisée des processus, pourtant maintenant largement démocratisée. L’isolation inhérente à la parallélisation a toujours autant été aussi importante que ne peut l’être la parallélisation.
Dans les années 1970, dans le développement des premiers noyaux Unix, chroot existait déjà. C’est la capacité de pouvoir créer un sous-système dans le système originel en changeant le système de fichier racine à un autre endroit. Dans les noyaux BSD, un peu plus tard, fût introduite aussi la notion de jail, représentant des sous-systèmes entiers étendant chroot avec des fonctionnalités réseau et ayant la capacité de se voir assigner des adresses IPs. De même, des technologies d’isolation propriétaires de grands constructeurs de serveurs, Sun Microsystems ou IBM, sont apparues mais ces dernières ont mûri de leur côté sans jamais vraiment interférer dans le cheminement vers ce qui est actuellement la conteneurisation. Le début des années...
Réseau
1. Le modèle OSI
OSI ou Open System Interconnection est une notion indispensable pour la bonne compréhension des mécanismes réseau et en particulier ceux impliqués dans OpenStack.
Il y a souvent beaucoup de confusions entre les notions de VLAN, d’adressage IP ou de routage qui entraînent une augmentation de la complexité déjà inhérente à Neutron, le service réseau d’OpenStack. Se référer au modèle OSI doit être un réflexe en présence de ces notions.
Comme son nom l’indique, OSI est donc un modèle. À l’instar d’un framework, c’est une conception idéale mais qui ne se retrouve que partiellement implémentée dans la réalité.
OSI subdivise la communication entre un expéditeur et un destinataire en sept couches :
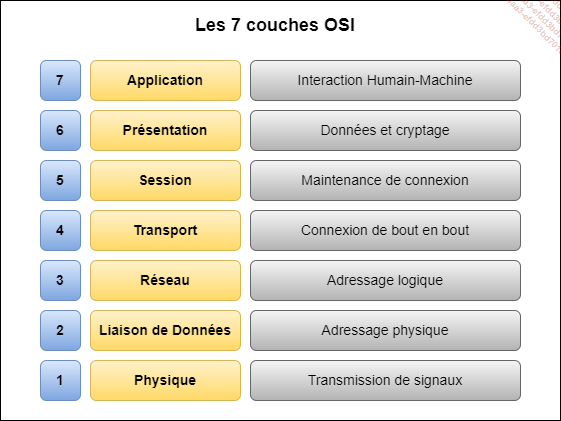
Les 7 couches OSI
Il est d’usage de représenter le modèle OSI de la couche la plus haute, qui est la couche application, à la couche la plus basse, qui est la couche physique. Cette logique vient surtout du fait que les données de la couche la plus haute sont encapsulées par le niveau suivant, à la manière des poupées russes. Ces données ont bien entendu des formats standardisés.
a. La couche 7, ou couche application
La couche 7 est la couche qui interagit directement avec l’utilisateur. C’est le protocole, et non le logiciel, qui constitue cette couche. Il est important de faire cette distinction puisqu’il peut exister plusieurs logiciels clients qui s’appuient sur d’autres mécanismes propriétaires spécifiques. La couche 7 couvre les besoins en transfert de fichiers, messagerie, annuaires, émulation de terminal... Ce sont des services normalisés : le dialogue avec ces services est standardisé...
Stockage
1. Les modes de stockage
a. Le stockage en mode fichier
Le plus connu et le plus familier des modes de stockage, le stockage en mode fichier, également appelé stockage basé sur des fichiers, est assez intuitif : chaque donnée est stockée en tant qu’élément d’information unique à l’intérieur d’un dossier qui peut être un sous-dossier d’un dossier parent, formant ainsi une arborescence. Pour pouvoir accéder à une donnée, l’ordinateur doit connaître le chemin à parcourir pour la trouver en parcourant les nœuds de cette arborescence. Les données stockées dans des fichiers sont organisées et récupérées à l’aide de quelques métadonnées qui indiquent à l’ordinateur où le fichier se trouve. Le système fonctionne comme un catalogue de bibliothèques.
Pour que l’ordinateur puisse comprendre le système d’organisation des fichiers, il faut que le disque soit formaté en un système de fichiers. Les capacités des systèmes de stockage en mode fichier sont vastes. Ceux-ci permettent de stocker à peu près tous types de données. Ils sont idéaux pour le stockage d’ensembles complexes de fichiers et rapides à parcourir.
Il existe tout de même un inconvénient : la profondeur de l’arborescence est limitée, à la fois techniquement mais aussi pratiquement : une arborescence trop profonde et avec trop de ramifications devient très vite pénalisante pour la constitution des métadonnées. Pour faire évoluer les systèmes de stockage en mode fichier, il faut donc ajouter de nouveaux systèmes, l’évolutivité horizontale, puisqu’il est impossible...
Queue management
1. Le protocole AMQP
AMQP ou Advanced Message Queuing Protocol, le protocole de gestion des files d’attente de messages, est une norme universellement reconnue qui fonctionne essentiellement sur la couche application. Elle est principalement utilisée pour développer une interopérabilité de communication entre les parties client et broker : c’est-à-dire que, peu importe la nature du message transmis par l’éditeur du message, le client récepteur le comprendra.
L’éditeur porte la responsabilité de la génération des messages tandis que les clients les collectent et les administrent. Le rôle des brokers, tels que RabbitMQ, dans tout ce processus est de faire en sorte qu’un message sûr, faisant partie de l’échange, aille directement de l’éditeur au client.
Les principales fonctionnalités clés sont le routage, l’orientation des messages et la mise en file d’attente. L’utilisation d’AMQP permet d’atteindre l’objectif d’interopérabilité, avec différentes configurations et infrastructures. Il permet aux développeurs de mettre en œuvre toute une variété de clients compatibles et de brokers approuvés.
a. Histoire
Créé par John O’Hara en 2003, AMQP a beaucoup évolué depuis sa création et possède une histoire riche. Alors que John est à l’origine d’AMQP, il travaillait avec JPMorgan Chase. La société JPMorgan Chase a conservé tous les droits d’AMQP et l’a même utilisé pour conclure un marché avec iMatrix Corporation. Ces deux entreprises ont utilisé AMQP pour concevoir la documentation des protocoles ainsi que le C Broker. Cette utilisation de l’AMPQ s’est poursuivie jusqu’à...
Base de données
1. SGBDR (Système de Bases de Données Relationnelles)
Un SGBDR est un ensemble logiciel de gestion de données qui permet en premier lieu le stockage des données respectant une structure basée sur des tables et en deuxième lieu une interrogation qui est normalisée et faite au travers d’un langage structuré : le SQL (Structured Query Language).
Les fonctions SGBDR les plus élémentaires sont liées aux opérations de création, de lecture, de mise à jour et de suppression, appelées collectivement CRUD (Create Read Update Delete). Elles constituent la base d’un système bien organisé qui favorise un traitement cohérent des données.
Le SGBDR fournit généralement des dictionnaires de données et des collections de métadonnées utiles pour la gestion des données. Ceux-ci prennent en charge par programme des structures de données et des relations bien définies. La gestion du stockage des données est une capacité courante du SGBDR, et elle est désormais définie par des objets de données allant des chaînes d’objets binaires volumineux - ou blob - aux procédures stockées. Les objets de données comme le blob étendent la portée des opérations de bases de données relationnelles de base et peuvent être gérés de différentes manières dans différents SGBDR.
Les SGBDR utilisent des algorithmes complexes qui prennent en charge l’accès simultané de plusieurs utilisateurs à la base de données tout en préservant l’intégrité des données. La gestion de la sécurité, qui applique un accès basé sur des stratégies...