
Notions avancées
OpenStack SDK
Le kit de développement SDK OpenStack est utilisé pour écrire des scripts d’automatisation Python afin de gérer les ressources cloud dans OpenStack. Le SDK implémente les bibliothèques Python à l’API OpenStack, permettant ainsi d’effectuer des tâches d’automatisation dans Python en appelant des objets Python au lieu d’utiliser directement des appels REST habituels.
Cette partie se propose d’explorer quelques idées directrices de la fonctionnalité de ce SDK.
1. Généralités
a. Installation
Le SDK OpenStack est disponible sur PyPI sous le nom openstacksdk. Pour l’installer, utilisez pip :
$ pip install openstacksdk Pour vérifier la version installée, appelez le module avec :
$ python -m version openstack b. Modes de connexion
Le SDK OpenStack utilise les modes de connexions habituels, à savoir soit en initialisant les variables d’environnement, soit en utilisant le fichier clouds.yaml.
Voici ci-dessous un exemple de connexion avec le fichier cloud.yaml :
clouds:
moncloud:
region_name: Antananarivo
auth:
username: 'moncloud'
password: XXXXXXX
project_name: 'demo'
auth_url: 'https://my.openstack'
import openstack
openstack.enable_logging(debug=True)
conn = openstack.connect(cloud='moncloud') Le SDK openstacksdk respecte toutes les variables OS_* normales. Il n’offre par contre pas de rétrocompatibilité avec les variables spécifiques au service telles que NOVA_USERNAME.
Si les variables d’environnement OpenStack ont été définies dans le shell courant...
Compute avancé
1. Changer la couleur de l’hyperviseur : intégrer VMware dans OpenStack
KVM est l’hyperviseur le plus déployé sur OpenStack. Ceci dit, rien n’empêche d’utiliser d’autres hyperviseurs, ce qui est d’ailleurs de plus en plus le cas surtout avec les systèmes de conteneurisation. Il arrive de plus en plus que les entreprises doivent faire cohabiter, que ce soit pour des raisons historiques, pratiques ou encore pour des considérations de compatibilité, plusieurs hyperviseurs au sein d’un même cloud.
De plus, dans le cas d’un cloud hybride, il faut souvent faire avec ce que propose le fournisseur. OpenStack permet l’intégration entre nova-compute et KVM, QEMU et LXC au moyen de libvirt et XCP via des API, tandis que vSphere, Xen ou Hyper-V peuvent être gérés directement via nova-compute.
a. Principes
Concrètement, le terme intégration au niveau de l’hyperviseur fait référence au pilote OpenStack qui sera fourni pour gérer vSphere par nova-compute. OpenStack expose deux pilotes :
-
vmwareapi.VMwareESXDriver : permet à nova-compute d’atteindre l’hôte ESXi au moyen du SDK vSphere.
-
vmwareapi.VMwareVCDriver : permet à nova-compute de gérer plusieurs clusters au moyen d’un seul serveur VMware vCenter.
Cette intégration permet d’exploiter des fonctionnalités avancées, telles que vMotion, vSphere HA et Dynamic Resource Scheduler ou DRS. Pour rappel :
-
vMotion est un composant de VMware vSphere qui permet la migration en direct d’une machine virtuelle en cours d’exécution d’un hôte à un autre sans temps d’arrêt.
-
vSphere de VMware fournit un utilitaire d’équilibrage de charge appelé DRS, qui déplace les charges de travail...
Linux bridge, Open vSwitch
Linux bridge et Open vSwitch sont les deux mécanismes qui se retrouvent le plus dans les implémentations réseau d’OpenStack. Ces mécanismes peuvent même se retrouver en même temps dans une même implémentation bien que dans la réalité, et dans un souci d’uniformité d’architecture, il est conseillé de n’en implémenter qu’un seul.
Souvent les distributions les plus historiques gardent Linux bridge et, au fur et à mesure de l’évolution de la plateforme, implémentent Open vSwitch. Chacun de ces mécanismes a ses avantages et ses limites. La tendance, il est vrai, est à la démocratisation d’Open vSwitch.
Ces deux mécanismes sont pilotés par le plug-in ML2 de Neutron qui a été vu dans le chapitre Concept de base d’OpenStack et peuvent l’un comme l’autre implémenter plusieurs types de réseaux, du VLAN, le plus massivement utilisé, aux overlays (VXLAN et/ou GRE qui n’est supporté qu’avec Open vSwitch) en passant par du flat. Il existe d’autres mécanismes d’implémentation L2 mais ils sont soit propriétaires (comme Cisco ou Brocade), soit exotiques, soit il peut s’agir de cas particuliers comme OVN (Open Virtual Networking), implémentation évoluée Open vSwitch utilisée notamment dans les récentes distributions de Red Hat Openstack Platform.
Pour rappel, ces configurations sont mises en place au niveau des nœuds compute. Naturellement, elles concernent plus la partie Provider que le Self-service.
1. Open vSwitch
Open vSwitch, ou OVS, est un switch virtuel, c’est-à-dire une émulation d’un switch physique mais pas seulement. Il émule aussi les câbles d’interconnexion et donc l’interconnexion...
Ceph
1. RADOS et OSD
Un des plus gros challenges imposés à l’ère du CI/CD est la haute disponibilité des systèmes de stockage qui deviennent des éléments critiques puisque souvent posés en bout de chaîne et responsables du maintien de l’état des applications. Ce challenge implique que le service de stockage ne doit non seulement pas tolérer les pannes mais ne doit pas non plus tolérer de pertes de données. Ce double objectif a été le fondement de la création de Ceph.
Il est vrai que contrairement aux autres éléments d’infrastructure, le stockage est le plus sujet aux pannes. Le périphérique de stockage peut tomber en panne, le système de fichiers peut être corrompu, l’ordinateur connecté au périphérique peut tomber en panne, etc. Des solutions, basées principalement sur la redondance matérielle, logicielle ou la réplication, ont été mises en place pour y pallier. Le challenge étant que l’utilisateur final n’ait pas à souffrir de l’impact de la mise en œuvre de ces solutions et encore moins à investir dans de coûteuses solutions sur du matériel ou de la technologie propriétaire. C’est ce défi que Ceph, qui de plus est désigné pour fonctionner sur du matériel standard avec des protocoles ouverts, relève.
a. OSD
Globalement, Ceph utilise comme unité de stockage l’OSD (Object Storage Daemon). C’est un ensemble constitué d’un disque sur lequel est installé un système de fichiers piloté par l’OSD pour former l’unité de stockage appelée node. C’est sur ces nodes que Ceph va distribuer et répliquer les données.
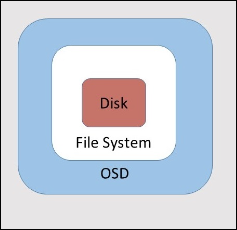
Architecture d’un OSD
Ceph...
Notions avancées sur le réseau d’OpenStack
1. Open Virtual Network
Open Virtual Network (OVN) est l’avenir de Neutron. À dire vrai, il en est même le présent : les dernières implémentations d’OpenStack et toutes les migrations vont vers OVN. Bien au-delà d’une évolution simple du réseau, OVN est une révolution : il casse plusieurs paradigmes et change complètement les fonctionnalités de Neutron : l’utilisation des namespaces et autre ipables pour l’implémentation des objets ou des groupes de sécurité ne sont plus de rigueur.
a. Architecture d’OVN
OVN est une série de daemons pour Open vSwitch qui traduisent les configurations de réseau virtuel en OpenFlow.
Il fournit une couche d’abstraction supérieure à Open vSwitch, fonctionnant avec des routeurs logiques et des switchs logiques, plutôt qu’avec des flux. OVN est destiné à être utilisé par un logiciel de gestion cloud, ou Cloud Management System (CMS). Il a été spécifiquement construit avec OpenStack comme CMS mais cela ne l’empêche pas d’être compatible avec d’autres CMS à l’aide du plug-in OVN/CMS.
L’architecture est composée des éléments suivants :
-
Le CMS : c’est l’endroit où les objets sont logiquement définis. C’est le CMS qui gère l’espace des noms de ces objets, comme les ID, les adresses MAC et IP, etc. Ces informations sont passées au composant suivant, le daemon ovn-northd.
-
NorthBound Database (NBDB) : cette base contient les définitions des objets créés dans le CMS. Il y a entre autres les tables Logical_Switch, Logical_Switch_Port, ACL...