
Concept de base d'OpenStack
Introduction : le parti pris
Dans les ouvrages où l’auteur est soumis à cet exercice de description de concepts et d’architectures, la tendance est souvent à une description littérale, brique par brique, composant par composant. En soi, il n’y a rien de mal à cela, mais force est de constater que, souvent, l’exercice revient à faire une redite de la documentation officielle. Et, dans le cas particulier d’OpenStack, celle-ci est particulièrement riche. Si riche qu’une redite n’aurait aucune valeur ajoutée.
Fort de ce constat, il a été décidé d’avoir une approche un peu plus pratique pour cette description. Elle consiste à examiner pas à pas la cinématique de création d’une machine virtuelle, depuis la demande initiale jusqu’à la mise à disposition fonctionnelle de celle-ci (en réseau, avec le stockage externe attaché). C’est à partir de cette cinématique que seront présentés les divers composants, à chaque fois qu’ils seront appelés.
Toutefois, certaines parties n’échapperont pas à une description littérale issue de la documentation.
1. Les concepts de base
OpenStack est un système d’exploitation de cloud. C’est utile de bien le préciser tant les confusions sont nombreuses, surtout avec tendance à le mettre au même niveau que, par exemple, de VMware ESX. Contrairement à celui-ci, qui est un hyperviseur, OpenStack est encore une couche au-dessus, comparable s’il devait y avoir comparaison avec le monde VMware, avec la solution vCloud.
En tant que système d’exploitation de cloud, OpenStack est donc l’interface qui va faciliter l’interaction entre un consommateur de ressources, englobant des personnes physiques...
Identité : Keystone
Le lecteur averti aura sans doute noté que le premier service auquel l’utilisateur est en contact est le Dashboard Horizon. Ce n’est pas tout à fait vrai en réalité. En effet, si le Dashboard est l’interface graphique d’interaction la plus naturelle avec OpenStack, il existe d’autres options comme la CLI (Command Line Interface) OpenStack ou le SDK (Software Development Kit). À vrai dire, à part la mire de connexion, le service d’identité est bien le premier sollicité pour interagir avec OpenStack.
Sur le schéma principal, quand la requête d’authentification est soumise par appel au service Keystone, identifié par le flux numéro 1, que ce soit depuis le Dashboard, le SDK ou la CLI OpenStack, Keystone évalue en réalité trois choses : l’utilisateur, le projet et le domaine.
1. Rôles de Keystone
a. Utilisateur, projets et domaines
Identité la plus évidente, l’utilisateur peut être associé soit à une personne soit à un service. En effet, aux yeux de Keystone, tout consommateur est représenté par un ID utilisateur unique. Évidemment, ces utilisateurs peuvent être regroupés dans des groupes.
Pour créer des ségrégations entre les divers utilisateurs de la plateforme, afin qu’ils puissent travailler sur un sujet commun, par exemple en ayant accès à des ressources communes sur la plateforme, le découpage par utilisateur et groupe ne suffit pas. Il ne permettrait pas par exemple à un utilisateur d’être administrateur sur une partie des ressources et simple utilisateur sur d’autres, cas qui n’est pas si rare. Il y a besoin de définir une entité qui reflète cette organisation et cette entité sera le projet...
Le service Image : Glance
Si Nova est celui qui reçoit le premier appel lors de la création d’une machine virtuelle (VM), hormis Keystone bien sûr, c’est Glance qui travaille en premier lieu. Dès que les caractéristiques de la machine virtuelle sont transmises à Nova, celui-ci va chercher l’image dans Glance pour construire la machine virtuelle grâce à un appel à l’API de celui-ci.
1. Architecture de Glance
En tant que service de stockage et de mise à disposition d’images, Glance doit assurer les fonctions suivantes : stocker les images, inventorier les images et les mettre à disposition.
OpenStack Glance a une architecture client-serveur exposant une API REST.
Un contrôleur de domaine Glance gère les opérations du serveur interne par couches. Des tâches spécifiques sont mises en œuvre par chaque couche.
Toutes les opérations sur les fichiers d’images sont effectuées à l’aide de la bibliothèque de look_store, qui est responsable de l’interaction avec les back-end de stockage, qu’ils soient externes ou locaux. La bibliothèque de look_store fournit une interface uniforme d’accès aux back-end de stockage.
Glance utilise une base de données centrale, Glance DB, qui est partagée entre tous les composants du système.
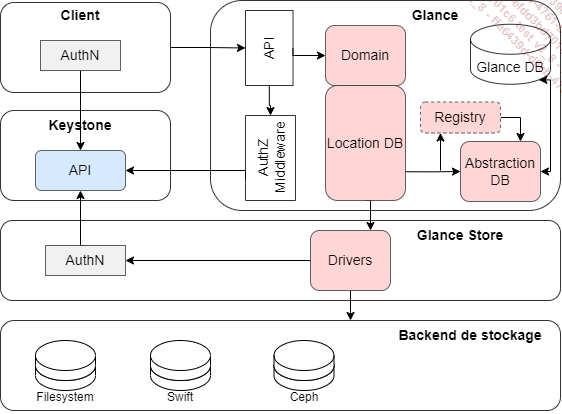
Architecture conceptuelle de Glance
Les composants suivants sont présents dans l’architecture Glance :
-
Un client : toute application qui utilise un serveur Glance.
-
API REST : les fonctionnalités de Glance sont exposées via REST.
-
Couche d’abstraction de base de données (DAL) : une API qui unifie la communication entre Glance et les bases de données.
-
Contrôleur de domaine Glance : middleware qui implémente les principales fonctionnalités telles...
Le service gestion des ressources : Placement
1. Généralités
a. Architecture
S’il y a un service méconnu dans OpenStack, c’est bien le service Placement. À l’origine, il faisait partie de Nova mais a été étendu à d’autres ressources. Placement fournit un service d’inventaire d’utilisation des ressources afin, qu’au moment opportun, l’API consommatrice puisse décider sur quel nœud sera activé un service.
L’architecture est assez directe : un WSGI couplé à une base de données. Il ne s’agit finalement que d’un inventaire couplé à un algorithme de choix.
Le modèle de données de placement est simple.
b. Workflow
Placement fonctionne de la manière décrite dans le diagramme suivant :
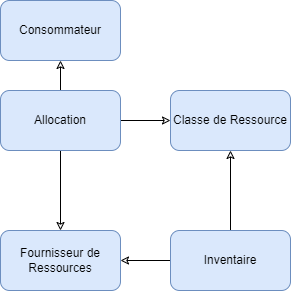
Le workflow de Placement
Tout d’abord, il y a un Consommateur qui sollicite une ressource. Par exemple une instance qui cherche le nœud compute sur lequel elle va démarrer. Des informations issues de cette demande, le bloc Allocation détermine les caractéristiques demandées par le Consommateur. Dans notre exemple, l’instance a besoin de 2 vCPU et cherche donc un compute qui peut satisfaire ce besoin. Le service d’Allocation s’adresse ainsi aux Fournisseurs de Ressources, ici des nœuds compute, après avoir filtré dans l’inventaire des ressources ceux qui possèdent les caractéristiques demandées de la classe de ressources, ici vCPU. L’inventaire peut par exemple faire sortir tous les nœuds qui ont plus de 2 vCPU et les présenter comme fournisseur de ressources. Le choix final du compute est fait avec une méthode qui sera vue ci-après.
2. Fonctionnement
Le service compute détermine sur quel nœud Host aggregates il doit...
Le service compute : Nova
Déjà en partie abordé lors des sections précédentes, le service Nova est le responsable de la gestion du cycle de vie de la machine virtuelle et de son interaction avec son environnement.
Cette partie ira directement à l’essentiel puisque même un livre entier ne suffirait pas à couvrir tous les sujets sur Nova.
1. Généralités
Nova est le composant historique d’OpenStack. Nova est l’orchestrateur qui va dialoguer avec l’hyperviseur dans le but de fournir des ressources de type machine virtuelle. Le dialogue entre le contrôleur sur lequel tourne le service Nova et l’hyperviseur est assuré au travers d’un agent Nova installé sur l’hyperviseur même.
Nova est agnostique de l’hyperviseur. C’est-à-dire que l’ordre de commissionnement d’une machine virtuelle est toujours la même peu importe la technologie employée par l’hyperviseur de KVM en passant par Xen ou même VMware... En pratique, Nova est intimement lié à KVM et la plupart des implémentations d’OpenStack, ainsi que les distributions, ont une forte tendance à rester sur cette configuration.
Pour pouvoir déployer une machine virtuelle sur l’hyperviseur, Nova doit disposer d’images préfabriquées et bootable fournies par Glance, couplées à un ensemble de caractéristiques prédéfinies, les flavors.
a. Architecture de Nova
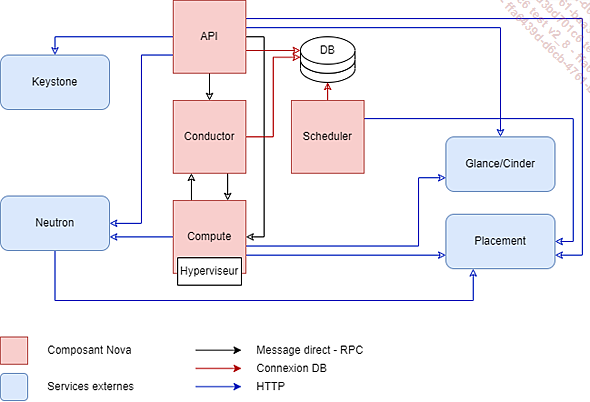
Architecture conceptuelle de Nova
Le point d’entrée du provisionnement est le composant nova-api. Ce service reçoit les ordres de création de la machine virtuelle avec les caractéristiques voulues.
nova-api interroge la base de données pour valider les aspects droits et récupérer les jetons d’authentification...
Le service réseau : Neutron
Réputé pour être le composant le plus difficile à appréhender d’OpenStack, le service réseau "Neutron" n’en est pas moins le plus fascinant. Pour pouvoir aborder ce sujet complexe, il est nécessaire d’avoir quelques notions en réseau, par ailleurs abordées dans le chapitre Rappel des notions techniques de base.
Dans le workflow de création d’instances, Neutron intervient plus en amont que ce que la logique peut laisser transparaître. En effet, la tendance est de penser que Neutron n’intervient que quand l’instance fait appel au service pour configurer son réseau. Neutron intervient bien avant, lorsque l’instance récupère les Metadata.
Avant de poursuivre sur la cinématique de provisionnement de l’instance, un petit rappel de ce qu’est Neutron s’impose.
1. Généralités
Neutron gère tous les aspects réseau pour l’infrastructure de réseau virtuel et les aspects de la couche d’accès à l’infrastructure de réseau physique. Le réseau OpenStack permet aux projets de créer des topologies de réseau virtuel avancées qui peuvent inclure des services comme un firewall, un load balancer et un réseau privé virtuel.
Le composant Réseau fournit des réseaux, sous-réseaux et routeurs comme des abstractions objet. Chaque abstraction a des fonctionnalités qui imitent son homologue physique : les réseaux contiennent des sous-réseaux, et les routeurs dirigent le trafic entre les différents sous-réseaux et réseaux.
Toute configuration réseau comporte au moins un réseau externe, le provider. À la différence des autres réseaux, le réseau externe n’est...
Le service Stockage : Cinder
1. Généralités
Cinder est le service de gestion du stockage bloc d’OpenStack. En réalité, il va bien au-delà du bloc, proposant aussi la gestion des stockages de type NFS dans les récentes évolutions.
Cinder s’intercale entre le système de stockage, le back-end et la machine virtuelle OpenStack. Il y a plus d’une centaine de back-end supportés à date, en tête desquels se retrouve Ceph. Cinder gère la création, le rattachement et le détachement de ces volumes aux machines virtuelles. À côté de ces fonctions de base, il sait cloner, faire des snapshots, migrer les volumes, répliquer, sauvegarder et restaurer...
Cinder peut aussi être utilisé en dehors d’OpenStack comme solution de SDS (Software Defined Storage).
a. Architecture logique
Cinder se compose de trois composants principaux qui s’exécutent en tant que processus indépendants et généralement sur différents nœuds.
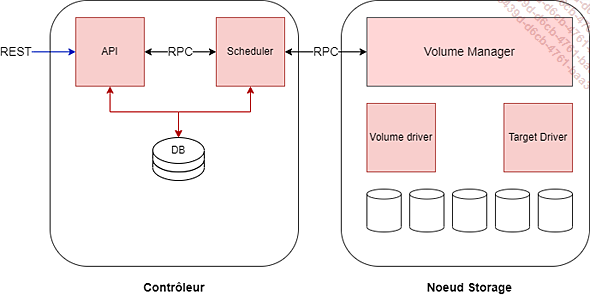
Architecture conceptuelle de Cinder
Tout d’abord, il y a le serveur API Cinder : cinder-api. Il s’agit d’un serveur WSGI fonctionnant à l’intérieur d’Apache2. Comme son nom l’indique, cinder-api est responsable de l’acceptation et du traitement des demandes d’API REST des utilisateurs et d’autres composants d’OpenStack et s’exécute généralement sur un nœud de contrôleur.
Ensuite, il y a cinder-volume, le gestionnaire de volume Cinder. Ce composant s’exécute sur chaque nœud auquel le back-end de stockage est attaché, et est responsable de la gestion de ce stockage, c’est-à-dire de la préparation, de la maintenance et de la suppression des volumes virtuels et de l’exportation de ces volumes afin...
Les autres services
1. Le PaaS avec OpenStack
a. Trove : service de bases de données
Avec les gestionnaires de packages, installer très rapidement des bases de données telles que MySQL, PostgreSQL ou même MongoDB devient une réalité, mais l’installation n’est jamais qu’une étape initiale. Une base de données fonctionnelle nécessite également des comptes d’utilisateurs et plusieurs étapes de configuration pour de meilleures performances et une meilleure sécurité.
Ce besoin de configuration supplémentaire pose des problèmes dans les environnements cloud. Tout peut toujours être installé manuellement dans une machine virtuelle avec des paramètres traditionnels, mais les utilisateurs du cloud souhaitent générer un environnement virtuel complet à partir d’un modèle. L’intervention manuelle est difficile et du moins plus que fastidieuse.
De plus, le client n’est pas censé se préoccuper de la configuration de la base de données dans l’environnement. Les utilisateurs s’attendent à pouvoir configurer un service dans le cloud d’un simple clic.
Ces considérations ont conduit au développement d’une nouvelle classe d’outils sous le nom de Database as a Service. L’objectif de DBaaS est de faciliter au maximum l’utilisation d’une base de données pour les clients du cloud. OpenStack le fait avec Trove.
Trove existe déjà depuis de nombreuses années. Le service n’a pas été facile à démarrer, et les développeurs ont eu besoin de plusieurs tentatives pour l’adoption de Trove en tant que partie officielle du programme OpenStack. L’objectif déclaré de Trove est de cacher la sous-structure technique complète...