
OpenStack en production
Design for Failure
Design for Failure (DFF) ou comment réfléchir à la conception de son architecture pour la rendre résiliente aux pannes, imaginées, réelles, passées comme futures.
De ce qui a été vu jusque-là, l’architecture fortement découplée des services d’OpenStack la rend de fait nativement résiliente aux pannes. Chaque service conserve une certaine indépendance et ne discute majoritairement que par API interposées.
Ce concept de DFF est en réalité une façon de réfléchir l’architecture en adoptant une position pessimiste. Cette affirmation ici est volontairement caricaturale. Il ne s’agit évidemment pas d’oublier le but premier de monter la plateforme : fournir un service fiable. Il s’agit d’adopter une attitude qui consiste à envisager le pire pour espérer le meilleur.
Le DFF impose une réflexion sur trois sujets : la tolérance aux pannes, la prévention des pannes et la supervision.
Avant d’aborder ces trois sujets, une catégorisation des divers services est nécessaire. En effet, une panne peut survenir autant au niveau des couches d’infrastructure matérielles qu’au niveau de l’applicatif qui tourne dans le conteneur. Pour ce faire, et dans le cas d’OpenStack, seront définies les catégories suivantes :
-
Niveau 1 : les infrastructures matérielles de base comme les serveurs physiques (qu’ils soient pour du baremetal ou hyperviseurs), les switchs et routeurs physiques.
-
Niveau 2 : les services OpenStack comme Nova, Cinder, Neutron... mais aussi les bases de données et gestionnaires de queues.
-
Niveau 3 : les services que fournit OpenStack comme les machines virtuelles, le stockage ou les fonctionnalités...
Infrastructure as Code
1. Généralités
a. Définitions
L’Infrastructure as Code (IaC), ou Infrastructure en tant que code, désigne l’approvisionnement par le biais de définitions déclaratives ou de scripts des éléments d’infrastructure tels que les serveurs physiques, virtuels, réseaux... par opposition à un provisionnement manuel ou même à un provisionnement automatisé hors références. En effet, une notion importante de l’IaC est d’avoir un référentiel des scripts de provisionnement, réputé ensuite refléter l’état actuel et réel de l’infrastructure.
Pouvoir considérer l’infrastructure comme du code permet d’apporter les avantages de l’automatisation, de la visibilité, de l’efficacité et de l’évolutivité à la gestion des infrastructures, conduisant ainsi à un déploiement plus rapide et plus fiable des applications, avec moins d’efforts manuels et de risques d’erreurs humaines ou de vulnérabilités de sécurité. Le découplage de la configuration avec l’implémentation rend plus faciles les opérations de migration, de création et de déploiement d’environnements.
Il est d’une importance capitale d’avoir un référentiel cohérent des codes dans tout système IaC. C’est une partie qui est souvent négligée mais qui pourtant fait toute la différence par rapport à un ensemble de scripts gérés dans un coin par un administrateur.
L’IaC utilise les notions de paradigmes déclaratifs ou impératifs.
b. Paradigmes déclaratifs ou impératifs
Notions héritées du monde de DevOps, un framework...
Les serveurs compute
1. Le choix des processeurs
Le choix de la ou des architectures de processeurs est d’une importance vitale pour le bon fonctionnement des hyperviseurs. Tout d’abord, il va sans dire qu’il est vivement conseillé d’avoir recours à des processeurs avec support de virtualisation au niveau matériel : VT-x pour la famille Intel et AMD-v pour la famille des AMD.
Il est également important de prendre en considération l’architecture même du CPU : qu’elle soit SMP, NUMA ou SMT. Pour rappel, SMP (Symmetric Multiprocessing) est l’architecture multiprocesseur où deux CPUs ou plus peuvent avoir accès simultanément aux ressources mémoires ou I/Os dans leur globalité. NUMA (Non-Uniform Memory Access) est l’architecture où les deux CPUs ou plus ont un accès direct à une partie de la mémoire et un accès indirect à la mémoire du voisin via un bus d’interconnexion. Enfin SMT (Simultaneous Multi-Threading) est une architecture dérivée de SMP où chaque processeur, au lieu d’accéder à un seul bus, possède plusieurs threads qui accèdent à plusieurs ressources en parallèle.
Dans OpenStack, les CPUs SMP sont appelés cores, les nœuds NUMA des sockets et les SMT des threads. Sachant qu’au niveau du vCPU, ces entités sont vues de la même manière et appelées abusivement cores. Par exemple, un serveur quadri processeurs en NUMA avec quatre cores chacun et deux threads par core possède quatre sockets, seize cores et trente-deux threads, soit trente-deux vCPUs potentiels.
Quand un vCPU est alloué à une machine virtuelle, le comportement par défaut de l’hyperviseur est de la laisser flottante et de ne solliciter la ressource qu’au moment...
Intégrer et sécuriser OpenStack
1. OpenStack et Identity Management (IdM)
Keystone est le centre de gestion non seulement des authentifications et autorisations nécessaires au fonctionnement du cluster mais aussi de l’ensemble des utilisateurs qui vont interagir que ce soit via les instances ou via des utilisateurs de services.
De base, Keystone stocke ces informations dans la base de données. Évidemment, il peut être nécessaire, voire indispensable, de l’intégrer à un système de gestion d’identités existant pour une parfaite intégration dans le système de l’entreprise.
a. Intégration avec Active Directory
Active Directory est sans conteste le système de gestion d’identités le plus rencontré en entreprise. Une configuration complète dépasserait le cadre de cet ouvrage. Les points d’attention à retenir sont :
-
Modifiez la configuration sur organizationalRole pour autoriser groupOfNames comme supérieur.
-
L’utilisateur qui modifie le paramètre de configuration du schéma doit faire partie du groupe Administrateurs de schéma.
-
L’utilisateur doit modifier la configuration sur le contrôleur de schéma Active Directory.
Du côté de Keystone, il est nécessaire d’activer Keystone v3.
b. Intégration avec un IdM basé sur FreeIPA
Pour les IdM basés sur FreeIPA, les comptes de service OpenStack, tels que Keystone et Glance ainsi que la gestion des autorisations et des rôles resteront dans la base de données Keystone.
En prérequis, il y a quelques préparations à faire :
Créez un compte de recherche LDAP. Ce compte est utilisé par Identity Service pour interroger le service LDAP IdM.
Créez un groupe pour les utilisateurs d’OpenStack....
Stockage et réseau
1. Stockage
Un déploiement cloud important nécessite une solution de stockage fiable, évolutive et robuste. Le stockage a toujours été le fer de lance de toutes les offres cloud, il est donc d’une importance capitale de garder un œil attentif sur cette partie.
L’infrastructure a été bien simplifiée grâce au SDS. Avec OpenStack, la gestion du stockage via la pile logicielle devient plus facile.
a. Le stockage éphémère et persistant
Pour le stockage éphémère, comme son nom l’indique, un utilisateur qui utilise activement une machine virtuelle dans l’environnement OpenStack perdra les disques associés une fois la machine virtuelle terminée. Ici, terminée ne veut pas dire reboot. Terminée est un état dans lequel l’instance est en pré-décommissionnement. Voir par ailleurs les divers états d’une instance dans le chapitre Concept de base d’OpenStack.
Lorsqu’un tenant démarre une machine virtuelle sur un cluster OpenStack, une copie de l’image Glance est téléchargée sur le nœud compute. Cette image est utilisée comme premier disque pour l’instance Nova, qui fournit alors un stockage éphémère. Tout ce qui est stocké sur ce disque sera perdu une fois l’instance Nova terminée.
Les disques éphémères peuvent être créés et attachés soit localement sur le stockage de l’hôte de l’hyperviseur, soit hébergés sur un stockage externe au moyen d’un montage NFS. En utilisant la dernière option, il est possible de migrer des machines virtuelles entre plusieurs nœuds compute puisque le disque racine de l’instance se trouve sur un stockage partagé...
Haute disponibilité
Implémenter de la haute disponibilité (HA) dans l’environnement de production n’est peut-être pas aussi simple que son nom l’indique : il s’agit d’éliminer tout point de défaillance unique ou SPOF (Single Point Of Failure) sur chaque couche de l’architecture. Les composants d’OpenStack peuvent être apportés et distribués dans différents nœuds tout en maintenant un esprit de collaboration, grâce notamment au service de messaging.
1. Bases de la haute disponibilité OpenStack
Une véritable plate-forme cloud OpenStack robuste inclut la tolérance aux pannes à tous les niveaux de l’architecture. OpenStack est conçu pour évoluer massivement et fournir une haute disponibilité en exploitant des techniques de haute disponibilité plus avancées à chaque niveau de l’infrastructure. Cela peut inclure le basculement automatique et la géo-redondance. Quelle que soit la raison d’une panne de nœud, les utilisateurs finaux doivent continuer à exécuter leurs applications et à générer des instances avec un minimum de perturbations ou de pertes de données.
Le facteur de disponibilité se mesure par la formule suivante :
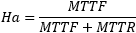
Où MTTF (Mean Time to Failure) est le temps moyen de fonctionnement du système avant sa défaillance et MTTR (Mean Time to Repair) le temps moyen pour remettre le système en fonctionnement.
Évidemment, définir un MTTF est très dépendant de la culture de l’entreprise : un temps de réponse dégradé (uptime) est un indicateur de pannes. L’importance de la philosophie Design for Failure prend ici toute sa dimension. Si la réflexion a été menée pour chaque couche...