
Power Query Online
Principes de base
1. Utilité et plus-value de Power Query Online
Power Query Online (PQO) est le module d’extraction de transformation et de chargement (ETL - Extract Transform and Load) des données du datamart, mais aussi de nombreuses applications Microsoft : Microsoft Fabric, Power Apps, Power Automate, Azure Data Factory, Dynamics 365 Customer Insights, les Dataflows et Excel pour Mac. Le fait de mutualiser un même outil dans plusieurs solutions permet à Microsoft de proposer un outil mieux développé et mieux testé.
Chaque version de PQO a une technologie de stockage différente. Ainsi, Power Query Online de datamart Power BI permet des sources variées, mais un stockage de données final disponible uniquement dans une base SQL Server alors que d’autres vont stocker en dataverse ou en data lake.
Concrètement, Power Query Online est un outil d’ingestion qui permet de se connecter aux sources de données, d’incorporer des données et de les préparer, c’est-à-dire de nettoyer les données et d’ajouter des colonnes supplémentaires si nécessaire pour constituer un magasin de données propres en libre-service avec des droits d’accès.
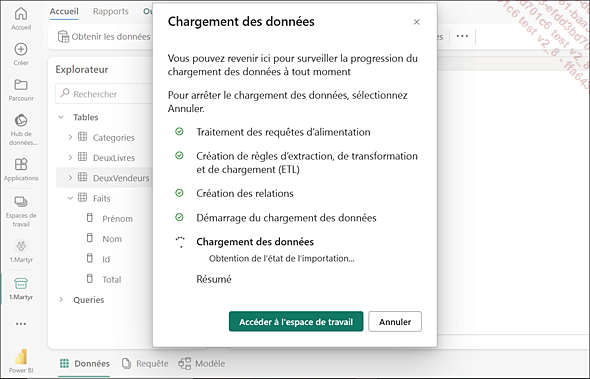
Comme en atteste le tout dernier écran à l’enregistrement de Power Query Online figurant ci-dessous, PQO alimente les données sources d’abord, crée et vérifie des règles de transformation avant de transformer ou de faire transformer les données puis termine enfin par le chargement sous forme d’un stockage en base puis d’une importation dans le datamart. Cet import permet une grande vitesse d’exécution, puisqu’il est en mémoire sur le serveur du datamart.
Le cas du Query Folding que nous verrons dans ce chapitre, section Le Query Folding et ses indicateurs, opère quelques transformations simples en amont à la source mais, in fine, la transformation finale se fait bien dans l’interface PQO, avant le chargement complet dans le datamart et son actualisation.
La force de PQO et de son langage M est de savoir :
-
ajouter des sources de données avec des connecteurs déjà testés et éprouvés sur de très nombreuses sources (dans les Dataflows, soit bien avant l’existence...
Différence entre Power Query Online et Desktop
Lorsque nous examinons la dernière documentation Microsoft de Power Query, rien ne transparaît clairement en matière de différence entre Power Query Online (PQO) et Power Query (PQ). Il y a souvent de mauvais conseils sur YouTube ou Internet, aussi il est important de lire ce qui suit.
1. Écarts à prendre en compte
Suite à de nombreux tests d’import de scripts M de Power BI Desktop vers Power Query OnLine, on peut constater qu’il y a bien des différences et souvent des ajustements à faire si on copie un script M issue du Desktop. Aussi une simple copie du code M depuis le Desktop ne fonctionne pas toujours en mode Online au moment du chargement dans le datamart.
En examinant les imports non fonctionnels de requêtes et en les croisant avec la documentation de PowerQuery, on trouve que souvent les différences proviennent :
-
d’une différence de paramétrage du contexte régional de PQO, ce qui sera expliqué dans la section Paramétrage du contexte régional. Cela peut perturber les fonctions sur les dates, les durées, les devises ou les nombres ;
-
des modalités d’ingestion des fichiers Excel présents sur le disque dur des PC ;
-
des modalités de connexion au local via la passerelle ;
-
des points non supportés par l’ETL Power Query OnLine (PQO) des datamarts. Par exemple, celui-ci ne permet pas de créer des requêtes basées sur des noms de colonnes définis dynamiquement ou des paramètres. Les transformations sont définies lors de la création de la requête PQO et ne peuvent pas être modifiées en fonction de conditions variables ,
-
des points non supportés par les datamarts, comme les types indiqués dans la section Types et autres points non supportés qui suit.
Dans Power Query Online, les formules personnalisées erronées génèrent le mot « Error » dans les cellules du tableau associé à l’étape, mais pas visuellement sur les étapes. Autant Power Query est souvent capable d’identifier dans Power BI Desktop sur quelle étape remonte une anomalie, autant PQO ne signale pas nécessairement les erreurs sur les étapes. Il faut...
Importer des données avec les connecteurs
Le datamart affiche un classement des connecteurs lorsque vous cliquez sur Obtenir les données - Nouvelles sources - Voir plus.
Les connecteurs Power Query Online sont classés en sept catégories :
-
Tous. Ceci permet d’effectuer une recherche générale sur tous les connecteurs.
-
Fichier (XL, CSV, PDF, XML, JSON, Parquet, Dossier SharePoint).
-
Base de données (MySQL, SAP, Amazon, Oracle…).
-
Power Platform (dont Power BI datamarts).
-
Azure (Azure SQL, synapse, AAS, blob storage, tables, Kusto, ADLS Gen2, Azure Cost Management, Databricks, etc.).
-
Service en ligne (où l’on trouve les listes SharePoint et les solutions partenaires comme Salesforce ou Databricks).
-
Autre (où l’on trouve notamment Odata, ODBC, API web, Table et Requête vides et beaucoup d’outils partenaires).
Il existe plus de cent connecteurs, aussi il est pratique d’utiliser la fonction Rechercher du moteur de recherche de connecteurs :
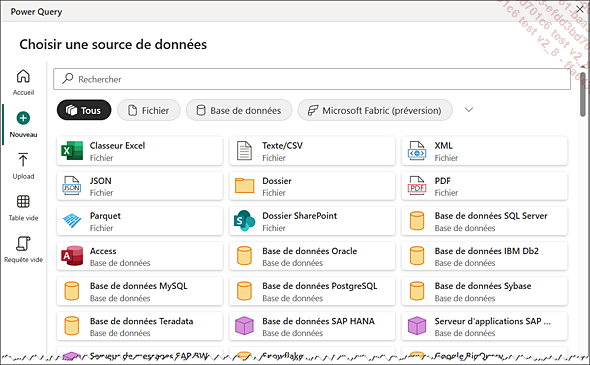
Le mode d’emploi pour effectuer une recherche par mot-clé est de passer directement par le ruban Accueil du datamart puis Obtenir les données ou bien par Power Query avec Transformer les données puis Obtenir les données.
Il n’existe pas de connecteur pour Azure Data Factory car c’est un ETL et non une source de données.
1. Importer une source SharePoint
Il y a deux points critiques dans l’importation d’une source SharePoint : l’authentification et l’URL. L’authentification se fait via un compte autorisé qui a droit de lecture sur le site ou la liste SharePoint. Nous allons voir deux sources : les fichiers et les listes.
Il faut éviter d’utiliser des sites personnels SharePoint et donc bien examiner l’URL du site SharePoint utilisé. Si un nom de personne est présent en début d’URL, veuillez changer de site. En effet, ceci gêne fortement le travail à plusieurs sur le datamart ou bien en cas de changement de propriétaire. En effet, à chaque changement de concepteur, la requête passe en erreur et il faut alors se ré-authentifier à toutes les sources SharePoint.
a. Fichier stocké dans SharePoint
Pour importer un fichier stocké dans SharePoint (comme Excel, CSV, PDF, JSON), il est important d’utiliser...
Les fonctions Power Query les plus utiles
1. Ajouter des tables spécifiques
Il est possible d’ajouter une table de données manuellement de deux façons :
-
en interface graphique du datamart,
-
en code M.
La première méthode est très facile à faire, mais non modifiable, car Power Query passe par un codage en dur en langage JSON, et est donc adapté à de toutes petites tables, ou à des tables non évolutives. La seconde permet de voir et corriger très facilement sous Power Query et donc adaptée aux tables personnalisées de toute taille et aux personnes un peu accoutumées au langage M. Essayons les deux méthodes. Dans les deux cas, le format % sera à faire via le modèle du datamart et non via Power Query.
a. Ajout de table en dur en interface graphique
Utilisez Datamart - Accueil - Entrer les données et, si l’écran est petit, allez dans Plus d’options (…) puis Entrer des données.

Une fenêtre Connexion à une source de données - Table vide apparaît.
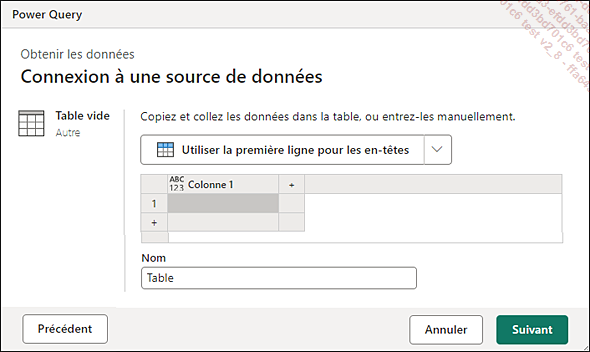
Vous pouvez y entrer les noms de colonnes et leur contenu.
|
%Inflation2024 |
%Inflation2025 |
|
5 % |
7 % |
|
10 % |
8 % |
Si vous ouvrez le fichier inflation.txt se situant à la racine du dossier de téléchargement 4.SourceExemples, vous trouverez ces données. Un simple copié-collé sur le titre permet de remplir également la table.
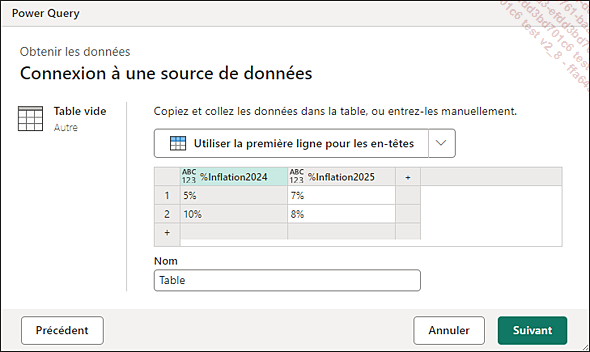
Cliquez sur le bouton Suivant.
Entrez en bas de la fenêtre le nom de la table : ici ScenarioInflation. Ceci va créer un code JSON qui sera la source. Ce JSON est encrypté et n’est pas lisible dans le code Power Query.
Si vos options de projet (ruban Accueil - Options - Projet - Chargement des données) avaient la case Détecter automatiquement les types de colonne et d’en-têtes pour les sources non structurées cochée, vous n’avez aucun typage à faire. Ceci est le paramétrage par défaut.
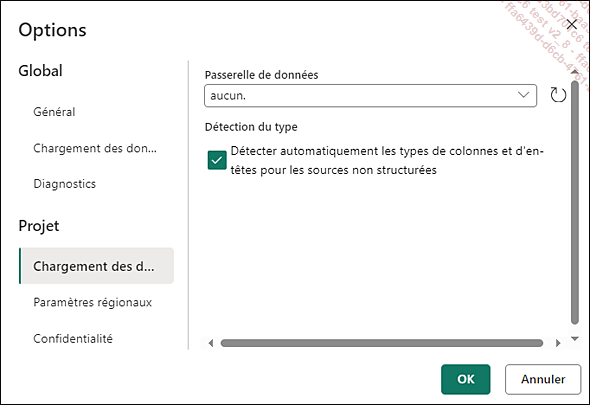
Sinon, sélectionnez les deux colonnes. Avec la transformation Groupe N’importe quelle colonne - Détecter le type de données sur les deux colonnes. Grâce à cette transformation, la colonne est automatiquement typée par Power Query Online, comme ici les pourcentages....
Le Query Folding et ses indicateurs
Les données des datamarts sont stockées dans Azure SQL DB. Un serveur SQL est un serveur de requêtage très rapide et très adapté au traitement sur de gros volumes. Il est plus rapide que Power BI à cet égard. Le Query Folding ou « pliage de requête » est une technique de Power Query qui analyse l’étape, examine si la requête est assez simple pour être transcrite en SQL, et passe la main à la base de données en amont pour exécuter cette requête au lieu de l’exécuter lui-même en aval dans le moteur Vertipaq de Power BI.
Ceci explique que le Query Folding ne fonctionne pas avec toutes les sources. Le Query Folding est supporté par :
-
les bases SQL du marché (Oracle SQL, SQL Server, Azure SQL...)
-
SQL Analysis Server et Azure Analysis Services
-
Exchange
-
Active Directory
-
Google Analytics
Le pliage de requête est partiel sur les sources Odata, et n’est pas supporté du tout par les autres sources, notamment les fichiers plats CSV ou Excel ni le stockage en blob comme Azure Blog Storage.
Voici le schéma du processus de Query Folding :
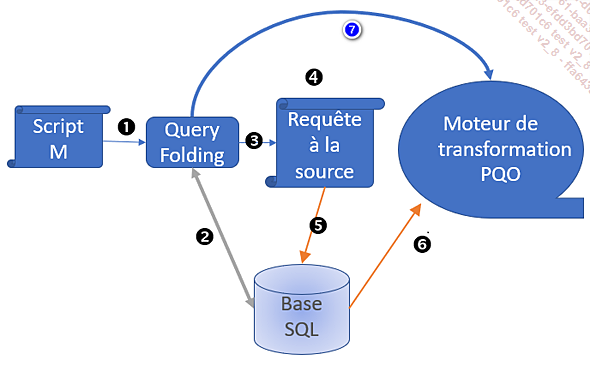
Le script M de PQO est analysé sous forme de « pli », étape par étape en (1) par le moteur d’optimisation du Query Folding. Celui-ci interroge en (2) la base SQL pour connaître les métadonnées : le nom des colonnes en SQL, le schéma des tables et les relations SQL. Ensuite, si l’étape M est exécutable en SQL, le moteur de pliage de requête élabore la requête SQL de chaque étape en (3) et envoie cette requête en (5) vers la base, qui envoie ensuite le résultat vers le moteur de MashUp PQO (le moteur de transformation Power Query Online). Le résultat venu de la base sous-jacente part en (6) vers Power Query.
Si le pli n’est pas traitable en SQL, le Query Folding est impossible, aussi la requête est-elle envoyée (7) au moteur de Mashup de Power Query Online, qui transformera la donnée comme demandé.
 indique à droite
que le Query Folding est impossible et une icône
verte
indique à droite
que le Query Folding est impossible et une icône
verte  apparaît...
apparaît...