
Les fondamentaux de l'intelligence artificielle
Ce que nous allons découvrir
Dans ce tout premier chapitre, nous allons débuter un voyage vous permettant d’explorer les multiples facettes de l’intelligence artificielle que nous aborderons sous son acronyme : "IA" dans cet ouvrage. Nous y verrons de nombreuses définitions, des concepts, des mots-clés et toutes autres terminologies vous permettant d’appréhender dans la meilleure des situations la poursuite de cet ouvrage.
Nous commencerons par l’histoire de l’intelligence artificielle afin d’en comprendre les enjeux se présentant à nous aujourd’hui et aborderons dans un second temps la définition de l’intelligence artificielle dite « générative ».
Tout cela nous amènera rapidement à la classification des différentes intelligences artificielles en examinant leurs approches et techniques aujourd’hui utilisées dans le but de créer des systèmes dits : « intelligents ». Parmi ces dernières, nous verrons les réseaux de neurones, les arbres de décision, et bien d’autres encore que vous aurez, ici, le plaisir de découvrir.
Nous plongerons ensuite dans un domaine qui vous est sans doute un peu familier, à savoir celui du « machine learning », constituant à lui seul et vous pourrez le constater...
L’histoire de l’intelligence artificielle
L’histoire de l’intelligence artificielle a été marquée par un nombre incalculable de moments de découverte, de défis, d’échecs, de promesses, mais également de prouesses que vous découvrirez tout au long de cet ouvrage. Chacun de ces éléments pourrait, à lui seul, faire l’objet d’un ouvrage à part entière.
Nous tâcherons d’être ici bien plus succinct en vous proposant dans ce tout premier chapitre d’explorer les jalons clés de l’évolution de l’intelligence artificielle qui vous le constaterez n’en est pas à premiers ses balbutiements. Nous mettrons ainsi en lumière les nombreuses avancées et prouesses technologiques qui ont façonné cette discipline complexe et tout bonnement fascinante !
L’histoire de l’intelligence artificielle débute peu après la Seconde Guerre mondiale, dans les années 1950, ce qui peut déjà sembler assez fou à l’heure où l’on pourrait considérer cet ensemble technologique comme étant émergent. Rassurez-vous toutefois, tout cela a beaucoup évolué depuis, nous parlons ici de fondation de l’intelligence artificielle, de socle, lorsqu’une poignée de chercheurs et scientifiques visionnaires ont commencé à imaginer la possibilité de créer des machines capables d’imiter, ne serait-ce que très brièvement l’intelligence humaine.
En 1956, des pionniers de l’informatique, des mathématiciens et des linguistes se sont réunis afin de mener des recherches sur des systèmes ayant la capacité à apprendre de manière autonome et de résoudre des problèmes considérés comme complexes. Le terme « intelligence artificielle » est alors naturellement apparu permettant de décrire cette capacité de la machine nouvelle et prometteuse.
Les premiers travaux ont conduit à la création de programmes informatiques permettant de prouver des théorèmes mathématiques, ce qui jeta les bases de l’apprentissage automatique. Dans cette même période, les chercheurs ont mis au point des langages de programmation informatique d’un style nouveau permettant de traiter des structures utilisant des symboles et des règles de traitement afin d’effectuer un certain nombre de taches, nous parlons alors de « structures symboliques », jetant ainsi les bases de la communication entre les machines et les humains.
Les années 1960 furent quant à elles marquées par un optimisme des plus audacieux. Les pionniers de l’intelligence artificielle rêvaient de machines capables de résoudre une multitude de problèmes tout aussi complexes les uns que les autres, allant de la traduction automatique à la robotique autonome. Un premier « Chatbot » conversationnel homme/machine a de fait été développé suivi par le robot « Shakey », tout premier du genre, qui fut créé dans le but de mener à...
L’intelligence artificielle générative
L’intelligence artificielle a évolué bien au-delà de simples programmes exécutant des tâches prédictibles. L’une des avancées les plus intrigantes et captivantes de l’IA est sa capacité à créer, à imaginer et à générer des contenus originaux. Cette facette fascinante est appelée : « IA générative ».
L’IA générative ouvre de fait de nouvelles perspectives dans l’innovation, dans l’art, dans le divertissement et même dans la résolution de problèmes complexes.
Elle repose sur des réseaux neuronaux d’apprentissage profond, tels que les réseaux génératifs adverses, en français, que vous retrouverez également en anglais sous son acronyme GAN (Generative Adversarial Networks), ainsi que les Transformers que nous aborderons au fur et à mesure dans cet ouvrage. Ces réseaux sont entraînés à partir d’énormes volumes de données et une fois entraînés, ils peuvent générer des données nouvelles et originales qui ressemblent à celles sur lesquelles ils ont été formés.
L’IA générative peut également créer des images...
La classification de l’intelligence artificielle
La classification de l’intelligence artificielle a pour vocation de permettre la compréhension des différentes catégories de systèmes développés dans ce domaine. Nous vous proposons ci-dessous les quatre domaines de classification dont vous devez avoir connaissance.
1. L’intelligence artificielle faible
L’IA faible, également connue sous les noms et acronymes : « d’IA étroite », de « Narrow Ai » ou bien encore « ANI », fait référence à des systèmes préalablement conçus dans le but de mener à bien une tâche précise et de manière intelligente. Elle est en fait considérée comme étant monotâche. L’IA faible se définie par la simulation d’un comportement humain, tout autant que par la restriction qu’on lui impose avec des contraintes se limitant à la tâche à accomplir. Elle est tout bonnement experte en son domaine de prédilection.
Malgré leurs apparences, ces systèmes sont donc plutôt limités dans leurs capacités et ne peuvent pas généraliser leur apprentissage à d’autres domaines.
Quelques exemples courants d’IA faible :
-
les systèmes de recommandation ;
-
les Chatbots ;
-
les moteurs de recherche ;
-
les voitures à conduite autonome ;
-
les outils de cartographie ;
-
les assistants virtuels ;
-
les systèmes de reconnaissance faciale ;
-
Siri, l’assistant virtuel Apple.
Comprenez par là, qu’une l’IA faible est orientée vers un objectif unique, bien précis, consistant à accomplir des tâches dédiées et spécifiques.
2. L’intelligence artificielle forte
Cette dernière est aussi connue sous les noms et acronymes de IA profonde, ou en anglais AGI pour Artificial General Intelligence. À la différence de l’IA faible, l’IA forte vise à imiter l’intelligence humaine à tous les niveaux.
Ces systèmes sont capables de comprendre, d’apprendre, de raisonner et d’effectuer des tâches complexes de manière similaire à un être humain. L’idée...
Les modèles d’intelligence artificielle : le machine learning
Dans ce chapitre, nous explorons les différents modèles d’intelligence artificielle, à commencer par le machine learning (ML) et ses algorithmes, véritable pierre angulaire de l’IA.
Nous aborderons ensuite le traitement du langage naturel (NLP) offrant à nos machines la capacité à comprendre le langage humain avant d’aborder le « deep learning » (DL) et la Vision par Ordinateur.
Nous découvrirons à travers ce chapitre comment chacun des modèles contribue à l’avancement de l’intelligence artificielle et ouvre la voie à des applications que vous pouvez d’ores et déjà considérer comme étant révolutionnaires.
Nous vous conseillons vivement de revenir régulièrement sur chacune de ces notions afin d’en maîtriser les interactions.
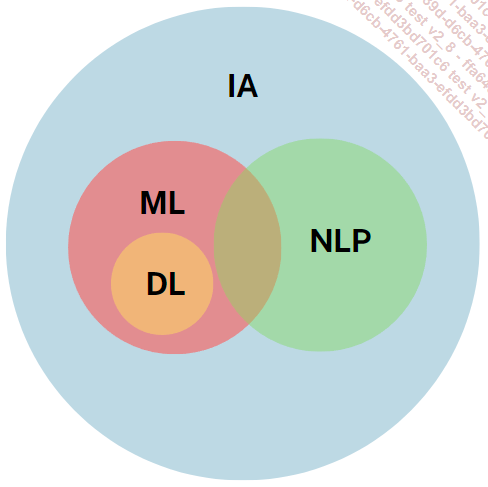
Les modèles d’IA
1. L’apprentissage automatique : le machine learning
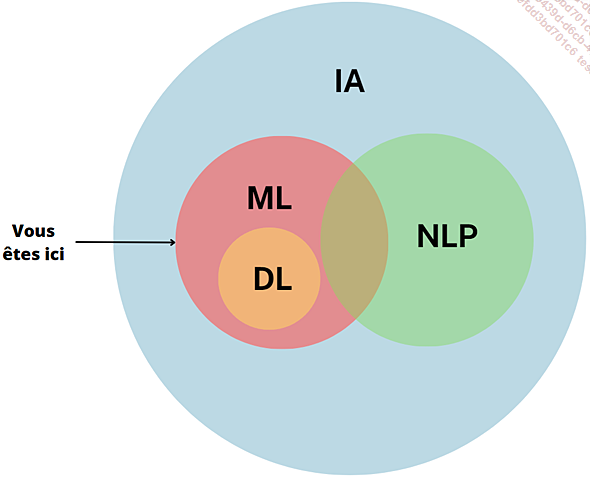
Machine learning
Le machine learning, abrégé ML, représente l’une des branches les plus captivantes de l’intelligence artificielle, un sujet qui pourrait remplir un livre entier à lui seul. Cette approche technologique révolutionnaire permet aux experts en données, communément appelés « Data Scientists », d’alimenter les algorithmes avec des ensembles de données, donnant ainsi aux machines la capacité d’apprendre et de prendre des décisions sans nécessiter de programmation informatique préalable.
En d’autres termes, au lieu de suivre des instructions strictes, les machines peuvent maintenant acquérir des connaissances à partir de données numériques préexistantes et s’améliorer au fil du temps grâce à un apprentissage continu et à l’augmentation du volume de données disponibles.
Le machine learning sert principalement à repérer des tendances et des similitudes, souvent désignées sous le terme de "patterns", qu’il s’agisse d’images, de mots, de statistiques, ou autres.
L’objectif sous-jacent est l’automatisation des tâches et la capacité à effectuer des prédictions en se basant sur des données passées.
Quelques exemples d’utilisation du ML :
-
La santé : détection des maladies.
-
Le secteur industriel : permettant de surveiller les capteurs et les défaillances.
-
Le commerce : tendances de vente.
-
Le tourisme : tarifications selon des tendances.
Nous aborderons trois formes que nous appellerons paradigmes d’apprentissage du machine learning :
-
L’Apprentissage Supervisé (Supervised Learning).
-
L’Apprentissage Non-Supervisé (Unsupervised Learning).
-
L’Apprentissage par Renforcement (Reinforcement Learning).
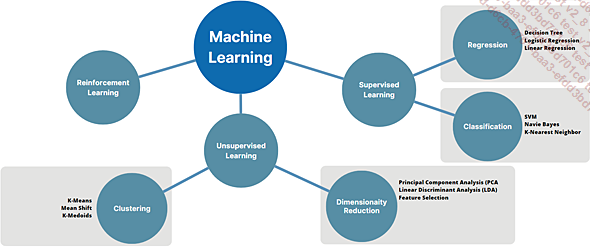
Paradigmes d’apprentissage du machine learning et ses algorithmes
2. L’apprentissage supervisé (Supervised Learning)
L’apprentissage supervisé est une approche visant à créer des modèles « prédictifs » pour anticiper par exemple, les besoins d’une...
Les principaux algorithmes supervisés (pour la prédiction de valeur)
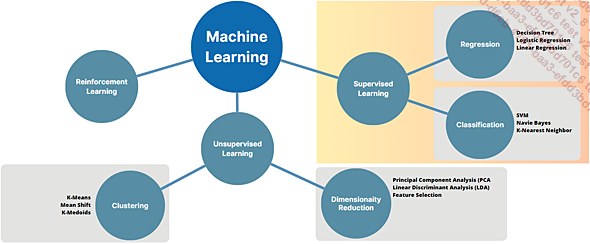
Algorithmes supervisés
1. Algorithme de régression : arbre de décision (Decision Tree)
La méthode de l’arbre de décision est un outil d’aide à la prise de décision et à l’exploration de données, illustré sous la forme d’un schéma arborescent. Chaque branche de l’arbre représente une série de tests pour prédire un résultat, avec des décisions prises à chaque extrémité. Les données sont divisées en sous-groupes à chaque test, et les prédictions sont basées sur les moyennes de ces sous-groupes. Par exemple, dans le contexte d’estimer le salaire d’un employé d’une entreprise de vente en ligne en fonction de son ancienneté et du nombre de dossiers traités, les tests successifs dans l’arbre guideront vers des prédictions. L’arbre peut diviser les employés en fonction de leur ancienneté, calculer la moyenne des salaires pour chaque groupe, puis prédire le salaire d’un employé particulier en se basant sur ces moyennes. L’arbre de décision est un outil d’apprentissage supervisé, où l’algorithme utilise des données passées pour effectuer des prédictions sur de nouvelles données en utilisant une approche de branches et de tests successifs.
2. Algorithme de régression : régression logique (Logistic Regression)
Les polynômes sont utilisés pour modéliser des relations mathématiques dans divers domaines, tels que la physique, l’économie ou l’ingénierie. Ils sont aussi souvent utilisés pour résoudre des équations et effectuer des calculs mathématiques. Il s’agit plus spécifiquement d’une expression mathématique que l’on peut construire en additionnant ou soustrayant différentes puissances d’une variable. Lorsque les données ne peuvent pas être séparées de manière linéaire, l’utilisation de polynômes permet à la ligne de séparation de faire des virages pour mieux aligner les observations....
Les réseaux de neurones (Neural NetWorks)
Nous venons d’explorer les bases du machine learning ainsi que ses différents systèmes d’apprentissage. Il est désormais temps de plonger dans une nouvelle composante essentielle de l’intelligence artificielle contemporaine, à savoir l’univers des réseaux de neurones. Cet élément peut sembler compliqué à appréhender, mais nous allons tâcher de le rendre facile à comprendre.
Mais alors qu’est-ce qu’un réseau de neurones, est-ce inspiré du fonctionnement du cerveau humain ? La réponse est oui.
Les réseaux de neurones sont bel et bien des modèles inspirés du fonctionnement de notre cerveau humain. Tout comme notre cerveau est composé de milliards de cellules appelées « neurones », un réseau de neurones artificiels est constitué de petits morceaux appelés « neurones artificiels ».
Ils sont conçus pour se parler les uns les autres dans un objectif d’apprentissage permanent et ont vocation à résoudre des problèmes de manière totalement similaire à notre propre système nerveux. Chaque neurone intercepte des informations, les mélange puis les envoie à d’autres neurones. En travaillant ensemble, ces neurones artificiels peuvent apprendre une multitude de choses, comme distinguer un animal dans une image.
Nous pouvons faire le parallèle avec l’apprentissage que nous avons vécu comme enfant, dès lors que nous apprenions à reconnaître les formes géométriques par exemple. Nos parents nous ont appris à dissocier ces formes telles que le carré ou le rond. Ainsi, petit à petit, nos jeunes cerveaux ont commencé à comprendre la différence entre ces formes. Et bien, notez que les réseaux de neurones fonctionnent de la même manière.
Les réseaux de neurones sont une des méthodes d’apprentissage automatique.
L’apprentissage des réseaux de neurones pourrait ressembler à l’apprentissage pour une personne lambda d’un nouvel instrument de musique. Au début, c’est complexe, mais plus nous pratiquons, plus nous devenons expert et pour cela les réseaux de neurones « écoutent » des tonnes d’exemples pour apprendre et s’améliorer.
Du côté de l’intelligence artificielle, il existe un cas concret d’apprentissage, par exemple comment l’intelligence artificielle arrive à reconnaître des chiffres écrits à la main. Et bien de la même façon que l’exemple précédent, elle regarde des milliers de chiffres écrits par des gens, puis elle apprend à les reconnaître par elle-même. Une fois qu’elle a appris, elle peut regarder un chiffre qu’elle n’a jamais vu et deviner correctement de quel chiffre il s’agit !
Dans le contexte du machine learning, les réseaux de neurones sont des modèles mathématiques inspirés du fonctionnement du cerveau humain.
Les réseaux de neurones ne sont...
Le traitement du langage naturel NLP
Nous vous proposons d’aborder dans ce chapitre une nouvelle branche toute aussi passionnante que les précédentes : le traitement du langage naturel (Natural Language Processing ou de son acronyme NLP).
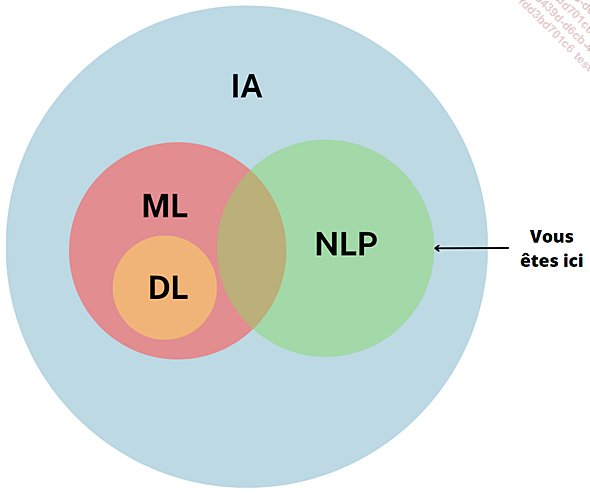
NLP
La raison d’être du NLP consiste à permettre la compréhension et la manipulation du langage humain par nos machines, rien que ça !
Pour l’histoire, le NLP remonte aux balbutiements de l’informatique dans les années 1950, mais son développement significatif s’est accéléré ces dernières décennies grâce aux avancées technologiques de l’intelligence artificielle.
Les tout premiers travaux se concentraient à cette époque essentiellement sur la traduction automatique. Une décennie plus tard dans les années 60, de nouvelles approches sont apparues permettant notamment d’adjoindre des règles grammaticales à la traduction automatique.
On assista d’ailleurs en 1964 à la sortie du tout premier robot conversationnel dénommé Eliza créé par Joseph Weizenbaum (https://fr.wikipedia.org/wiki/ELIZA).
Dans les années 1990, l’approche statistique a également fortement gagné en popularité. Les chercheurs ont utilisé des modèles basés sur des statistiques et les probabilités afin de résoudre les fortes lacunes du NLP, qu’étaient la reconnaissance de la parole et la traduction automatique.
C’est au cours de la dernière décennie que l’utilisation des réseaux de neurones profonds a révolutionné le NLP. Les modèles de traitement du langage basés sur l’apprentissage profond ont permis d’obtenir des performances absolument remarquables dans de nombreuses tâches, telles que la traduction automatique, la génération de texte et l’analyse des sentiments.
Aujourd’hui, les deux principales tâches du NLP sont :
-
la compréhension du langage naturel : en anglais Natural Language Understanding (NLU) ;
-
la génération du langage naturel : en anglais Natural Language Generation (NLG).
1. La compréhension du langage naturel (NLU)
La compréhension du langage naturel (NLU) constitue l’art de déchiffrer le sens caché au sein d’un texte ou d’une conversation, bien au-delà d’une simple traduction.
Dans le domaine de la NLU, de nombreuses techniques sont employées. Nous ne les aborderons pas dans le détail de ce chapitre, toutefois ces dernières sont principalement :
-
La segmentation du texte : activité de découpage.
-
L’identification des entités nommées : activité d’identification.
-
La démystification des ambiguïtés sémantiques : activité permettant de donner du sens pour les mots et expressions.
-
La mise en contexte des éléments...
Le deep learning : apprentissage profond
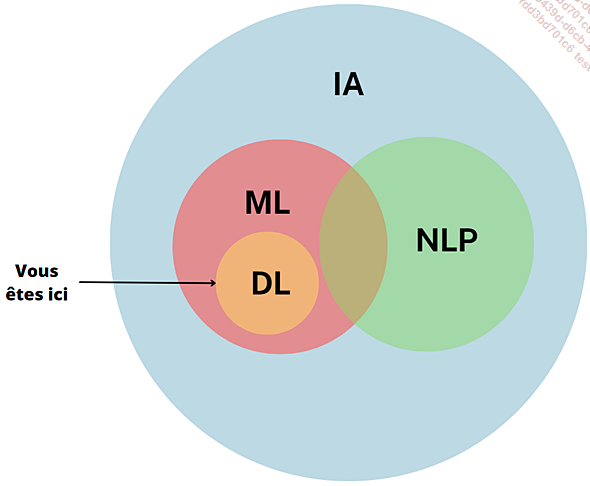
Deep learning
Le deep learning est une branche de l’apprentissage automatique (machine learning) que nous avons perçu en tout début de chapitre. Vous le reconnaîtrez également sous le nom « d’apprentissage profond ».
La raison d’être du deep learning est de permettre aux machines d’apprendre à partir de données massives et de manière autonome.
Son objectif final consiste à résoudre des problématiques complexes.
1. L’histoire du deep learning
L’histoire du deep learning est une fascinante épopée technologique qui a vu cette branche de l’intelligence artificielle évoluer et prendre de l’ampleur au fil des décennies. Voici une rétrospective des moments clés de l’histoire du deep learning :
Dans les années 1940, les premiers travaux dans le domaine des réseaux neuronaux, qui constituent encore la base du deep learning, ont été réalisés par des chercheurs tels que Warren McCulloch et Walter Pitts.
Leurs travaux ont posé les fondations théoriques des réseaux neuronaux en tant que modèle mathématique afin de simuler le fonctionnement du cerveau.
Au cours des décennies suivantes, l’intelligence artificielle a connu diverses avancées, mais les réseaux neuronaux sont restés en grande partie en sommeil.
Les chercheurs ont plutôt privilégié d’autres approches, comme les arbres de décision et les machines à vecteurs de support. En anglais Support Vector Machines (SVM), pour résoudre des problèmes d’apprentissage automatique.
Le deep learning a connu un rebond au début des années 2000 grâce à des avancées technologiques et des percées théoriques révolutionnaires. L’augmentation de la puissance de calcul, en particulier avec l’utilisation de GPU (puces graphiques), a permis de former des réseaux neuronaux profonds bien plus rapidement.
Des chercheurs ont également développé des techniques d’entraînement plus redoutables. Le deep learning est ainsi devenu de plus en plus populaire au cours de la dernière décennie.
Des réseaux neuronaux profonds, avec de nombreuses couches cachées, ont été développés pour résoudre des problèmes complexes tels que la reconnaissance d’images, la traduction automatique, la reconnaissance vocale et la conduite autonome.
2. Le deep learning
Tout comme sa grande sœur « machine learning », le « deep learning » s’inspire du fonctionnement du cerveau humain, où...
Conclusion
Dans ce premier chapitre, nous avons parcouru les fondamentaux de l’intelligence artificielle, un domaine fascinant qui ne cesse de façonner notre monde de manière profonde.
De l’histoire passionnante de l’IA, de ses débuts modestes à ses avancées spectaculaires, en passant par les différentes classifications des intelligences artificielles, nous avons exploré les bases essentielles, certes longues, mais à nouveau essentielles qui sous-tendent ce domaine en constante évolution.
Nous avons également plongé dans le monde captivant de l’intelligence artificielle générative, où les machines sont capables de créer de nouvelles réalités artistiques et fonctionnelles.
Nous avons également abordé le machine learning, avec ses algorithmes puissants qui permettent aux ordinateurs d’apprendre à partir de données, tout comme les réseaux de neurones, qui ont révolutionné la manière dont nous abordons des tâches complexes telles que la vision par ordinateur et le traitement du langage naturel.
Le chapitre a également exploré l’univers du deep learning, mettant en lumière la façon dont les réseaux de neurones profonds ont ouvert de nouvelles perspectives passionnantes pour l’IA, notamment dans la reconnaissance d’images...





