
Fiches outils - Être résilient face aux perturbations et attaques
La matrice de criticité des systèmes
La première étape doit permettre de savoir les priorités lors de la reprise après sinistre. Cet exercice s’avère plus compliqué qu’il n’en a l’air. En effet, de nombreuses organisations ne disposent pas de la liste des systèmes. Une fois la liste clarifiée, les systèmes peuvent être catégorisés selon quatre niveaux de criticité :
-
Critique : systèmes qui influencent le niveau de sécurité d’un lien ou d’un système, qui peuvent mettre l’organisation à risque, systèmes qui sont nécessaires au bon fonctionnement d’autres systèmes à priorité haute. Ces systèmes doivent être restaurés en premier lieu.
-
Haute : systèmes nécessaires à l’organisation dans les activités au quotidien. Dû à l’importance de ces systèmes, il est nécessaire de se focaliser sur ceux-ci dès que les systèmes fondamentaux (c’est-à-dire catégoriés comme critiques) sont revenus à l’état de marche.
-
Moyenne : systèmes utiles à l’organisation dans les activités au quotidien mais qui sont en soi des facilités. Ces systèmes peuvent être restaurés une fois les autres systèmes nécessaires à l’organisation ont été rétablis.
-
Basse : ces systèmes ne sont pas nécessaires pour l’organisation, bien que certainement cela amène des facilités aux collaborateurs. Ces systèmes pourront être rétablis...
Le contenu d’un plan de continuité
Le plan de continuité d’activité doit contenir de nombreuses informations pour permettre à l’organisation de fonctionner malgré un sinistre en cours. Tout d’abord, il s’agit d’identifier les risques majeurs que l’organisation peut subir, tels que des catastrophes naturelles, des pannes sévères ou encore des attaques informatiques. Plus récemment, de nombreux plans ont été mis à jour pour intégrer les pandémies, ce nouveau type d’évènement pourrait en effet être plus fréquent que par le passé. En effet, la pandémie est venue avec de nombreuses contraintes mais aussi des obligations que les organisations n’avaient pas anticipées, provoquant une ruée vers le matériel informatique mais aussi de nombreuses modifications de procédures, le tout en urgence.
En plus des risques, ce plan indique également les services critiques, ceux qui impactent fortement l’organisation et qui peut la mettre en situation de risque mais aussi les plans opérationnels : les rôles, les procédures pour ne citer que les principaux. Il se peut qu’il soit nécessaire de faire intervenir des ressources externes. C’est là que la planification s’avère d’autant plus intéressante...
Le plan de reprise après sinistre
Le plan de reprise après sinistre doit contenir l’ensemble des étapes à suivre pour revenir à l’état initial malgré l’évènement qui vient de survenir. Ce plan repose notamment sur la matrice de criticité décrite ci-dessus. Étant donné qu’un sinistre peut impacter un seul système, il est possible de faire des plans de reprise pour ce système donné. Cependant, il est nécessaire d’avoir un plan global qui fait le lien avec les autres afin d’assurer la bonne coordination des actions au niveau global. Préparer un tel plan requiert de comprendre l’architecture du système mais aussi les opérations qui y sont relatives.
La gestion de la connaissance est de ce fait un élément clé. La gestion de la connaissance est présentée au chapitre « Accompagner les utilisateurs ».
Sur la base de ces informations, il s’agit alors d’établir qui et quand effectuer des actions. Cette notion de responsabilité est importante et doit être communiquée en amont aux différents intervenants afin d’assurer une bonne exécution le moment venu. Une attention particulière est portée sur les vérifications des différentes actions avant de rendre le système accessible aux utilisateurs.
|
# |
Objectifs |
Criticité |
|
1 |
[Nom du système] |
Critique |
|
[Justification]
|
||
|
2 |
Active Directory (identification) |
Critique |
|
L’Active Directory est le fournisseur d’identités tant pour les personnes que les machines
|
La matrice de priorisation d’un incident
La définition de l’impact peut varier d’un système à l’autre et de ce fait, il est important de définir des critères au préalable, et ce pour chacun de ces systèmes. Ainsi, on peut se poser des questions telles que celles ci-dessous pour déterminer l’impact :
-
Des opérations clients sont-elles impactées ?
-
Les coûts d’opération sont-ils impactés ?
-
Des pertes sont-elles à prévoir, que ce soit à la suite de pénalités ou de coûts supplémentaires ?
-
Des utilisateurs ou clients clés sont-ils impactés ?
Pour ce qui est de l’urgence, les questions suivantes devraient faire l’affaire :
-
Cela bloque-t-il des opérations à cet instant ? Si non, quand cela risque-t-il d‘arriver ?
-
L’impact financier est-il fonction du temps ?
-
La réputation de l’organisation peut-elle en souffrir ?
En répondant à ces questions, il est alors possible de définir tant l’impact que l’urgence. Généralement, à chaque question, des propositions sont associées et la valeur la plus élevée l’emporte alors. Prenons comme exemple la première question posée : « Des opérations clients sont-elles impactées ? »...
Le rapport d’incident
Le rapport d’incident veille à clarifier ce qu’était l’incident et surtout les raisons pour lesquels cet incident est survenu et comment il a été résolu, et ce dans le but d’apprendre pour réduire le risque de récurrence mais aussi d’améliorer la résolution d’un futur incident, dans le cas où cela surviendrait à nouveau. Le rapport d’incident n’est préparé que dans le cas d’un incident majeur (cf. chapitre « Être résilient face aux perturbations et attaques », section « Les incidents majeurs »).
Rapport d’incident : <Reference de l’incident> - <Titre de l’incident>
|
Identification de l’incident |
|
|
Titre de l’incident |
<Description simplifiée> |
|
Symptômes |
<Messages d’erreur, situation visible, etc.> |
|
Impact pour les utilisateurs |
<Impossibilité d’effectuer une opération particulière, donnée incomplète ou incorrecte> |
|
Utilisateur(s) affecté(s) |
<Groupes d’utilisateurs qui ont été impactés par le problème> |
|
Date et heure de début de l’incident |
<Pour savoir depuis combien de temps le problème est en cours> |
|
Résolution de l’incident |
|
|
Cause de l’incident |
<Explication... |
La matrice d’escalade
La matrice d’escalade a pour but de définir quand une escalade doit avoir lieu et vers qui. Pour être précis, nous devrions parler des matrices d’escalade. En effet, il en existe plusieurs. Parmi les plus fréquentes en informatique, nous aurons la matrice d’escalade des incidents, celles liées aux problèmes au sein des projets et bien d’autres. Il existe d’ailleurs autant de formats que de périmètres couverts. L’important est que les gens se comprennent. La matrice peut se baser sur des critères simples, les déclencheurs :
|
Rôle |
Contact |
Déclencheurs |
|
Team leader |
<Nom de la personne>, <Téléphone/email, en fonction du mode d’escalade> |
8 heures après <évènement, par exemple un incident> |
|
Gestionnaire de la relation |
<Nom de la personne>, |
24 heures après <évènement, par exemple un incident> - ou - Le nombre d’occurrences de l’événement augmente |
|
Responsable du service |
<Téléphone/email, en fonction du mode d’escalade> |
[…] |
Une autre approche est d’utiliser la matrice de priorisation présentée ci-dessus. Lorsque l’incident est majeur, le responsable du service doit, par exemple, directement être notifié, voire consulté.
Un modèle...
Les 5 pourquoi
Lorsqu’un incident ou un problème survient, on ne voit généralement que la partie émergée de l’iceberg. Il s’agit alors d’identifier le pourquoi. Dans le cas d’un incident, il est probable qu’un problème soit identifié au travers de cette approche. Tout du moins la cause réelle de l’incident sera identifiée. En moyenne, la cause de l’incident et l’incident lui-même sont séparés de cinq niveaux au maximum, ce qui explique pourquoi cet outil s’appelle les « 5 whys » (les 5 pourquoi).
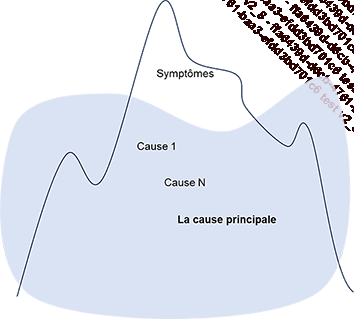
Le formalisme est simple et facile à mettre en place :
<Description du symptôme>
-
Pourquoi (1) ce symptôme ? Parce que <cause 1>
-
Pourquoi (2) <cause 1> ? Parce que <cause 2>
-
Pourquoi (3) <cause 2> ? Parce que <cause 3>
-
Pourquoi (4) <cause 3> ? Parce que <cause 4>
-
Pourquoi (5) <cause 4> ? Parce que <cause 5>
Dès qu’il n’est plus possible d’identifier une raison autre, c’est sur ce point qu’il est nécessaire de travailler et non pas sur le symptôme sans quoi il y aura récurrence de l’incident.